http://www.linuxjournal.com/content/real-time-rogue-wireless-access-point-detection-raspberry-pi
Years ago, I worked for an automotive IT provider, and occasionally we went out to the plants to search for rogue Wireless Access Points (WAPs). A rogue WAP is one that the company hasn't approved to be there. So if someone were to go and buy a wireless router, and plug it in to the network, that would be a rogue WAP. A rogue WAP also could be someone using a cell phone or MiFi as a Wi-Fi hotspot.
The tools we used were laptops with Fluke Networks' AirMagnet, at the time a proprietary external Wi-Fi card and the software dashboard. The equipment required us to walk around the plants—and that is never safe due to the product lines, autonomous robots, parts trucks, HiLos, noise, roof access and so on. Also when IT people are walking around with laptops, employees on site will take notice. We became known, and the people with the rogue WAPs would turn them off before we could find the devices.
The payment card industry, with its data security standard (PCI-DSS), is the only one I could find that requires companies to do quarterly scans for rogue WAPs. Personally, I have three big problems with occasional scanning. One, as I said before, rogue WAPs get turned off during scans and turned back on after. Two, the scans are just snapshots in time. A snapshot doesn't show what the day-to-day environment looks like, and potential problems are missed. Third, I think there is more value for every company to do the scans, regardless of whether they're required.
Later, when I was a network engineer at a publishing company, I found it was good to know what was on my employer's network. The company wanted to know if employees followed policy. The company also was worried about data loss, especially around a couple projects. Other companies near us had set up their own wireless networks that caused interference with the ones we ran. Finally, I had to worry about penetration testers using tools like the WiFi Pineapple and the Pwn Plug. These allow network access over Wi-Fi beyond the company's physical perimeter.
One thing I always wanted was a passive real-time wireless sensor network to watch for changes in Wi-Fi. A passive system, like Kismet and Airodump-NG, collects all the packets in the radio frequency (RF) that the card can detect and displays them. This finds hidden WAPs too, by looking at the clients talking to them. In contrast, active systems, like the old Netsumbler, try to connect WAPs by broadcasting null SSID probes and displaying the WAPs that reply back. This misses hidden networks.
A couple years ago, I decided to go back to school to get a Bachelor's degree. I needed to find a single credit hour to fill for graduation. That one credit hour became an independent study on using the Raspberry Pi (RPi) to create a passive real-time wireless sensor network.
About the same time I left the automotive job, Larry Pesce of the SANS Institute wrote
"Discovering Rogue Wireless Access Points Using Kismet and Disposable Hardware". This was a paper about real-time wireless sensors using the Linksys WRT54GL router and OpenWRT. But, I didn't find out about that until I had already re-invented the wheel with the RPi.
Today lots of wireless intrusion detection systems exist on the market, but as listed in the Hardware sidebar, mine cost me little more than $400.00 USD to make. Based on numbers I could get, via Google Shopping, using Cisco Network's Wireless IDS data sheet from 2014, a similar set up would have cost about $11,500 USD. I've been told by a wireless engineer I know that he was quoted about twice that for just one piece of hardware from the Cisco design.
Hardware
Below is the hardware per sensor—your prices may vary depending on where you buy and what's on sale.
Cost of parts: $69.95 per sensor; I used six Raspberry Pis in the project.
Raspberry Pi Wireless Sensor Drone:- Raspberry Pi Model B: $35.00 (found on sale for $29.99).
- 5v 1amp power supply: $9.99.
- Plastic Raspberry Pi case: $8.99.
- TP-Link TL-WN722N: $14.99.
- Class 10 SDHC 8-gigabit Flash card: $5.99.
Network:- Cat 5e cable between 25–50' long: already had.
- Linksys WRT54GL: already had.
- Linksys 16-port workgroup switch: already had.
Monitor and Kismet Sever:- Laptop running Xubuntu Linux VM: already had.
When I started looking into using the RPi for this, I kept coming across people using the RPi and Kismet for war driving, war walking and war biking. David Bryan of Trustwave's Spider Labs did a blog post in 2012 called
"Wardrive, Raspberry Pi Style!" where he talked about using Kismet with the RPi to track WAPs on his walk and drive around his area. He used a USB GPS device to map out where the access points were.
Because the RPis are used as stationary devices, I didn't need GPS. One thing I did need though was a rough idea of where to place the sensors. Based on readings, Wi-Fi is good for about 328 feet (100 meters) with the omnidirectional antenna being used on the TP-Link card indoors. Having the existing wireless survey (or doing one) will be useful (see Wireless Survey sidebar). It will let you know where the existing WAPs are. This information also could come from the network documentation, if it exists. It is important to keep the detectors from being overpowered by approved access points. The wireless survey or network documentation also should provide the BSSIDs for the approved devices to be filtered out.
Wireless Survey
A wireless survey is usually a map of a building or location showing the signal strengths associated with wireless access points. Surveys are usually the first step when a new wireless network is installed. Surveys give the installers how many WAPs are needed, where they should be spaced, and what channels would be best to use in those areas.
Surveys normally are done with a WAP and a Wi-Fi-enabled device. The WAP is placed in a location, and signal strength is recorded as the client is moved around the area.
A rogue WAP or a survey WAP can be built from a Raspberry Pi with a wireless card and Hostapd.
Most on-line documentation for a Hostapd WAP says to bridge the network cards on the RPi. This can be skipped if the WAP will not be used with clients that connect to the Internet.
The RPis have no shortage of operating systems to run. My choice for this project was to run Kali Linux on the RPi, with Airodump-NG and Kismet. Originally, it was going to be just Kali and Kismet, but I ran into some limitations. The reason I chose Kali for this project, was the hardware drivers for the network card I used didn't need to be recompiled. Kali also came with Airodump-NG preinstalled, and an
apt-get update && apt-get install kismet took care of installing the rest of what I needed.
Kali Linux:
Kali Linux is the new version of Backtrack Linux—one of the specialized Linux distributions for penetration testing and security. It is currently based off Debian Linux, with security-focused tools preinstalled. Kali runs everything via the root login.
Kali has builds available as ISOs and VMware images in 64-bit, 32-bit and custom-built ARM images for single card boards, Chrome OS and Android OS devices.
Airodump-NG
Airodump is a raw 802.11 packet capture device. It is part of the Aircrack-NG suite. Normally, Airodump-NG will capture a file of packets to be cracked by Aircrack-NG. However, in my case, I wanted the feature where Airodump-NG can list the clients and access points it sees around it, which is about 300 feet indoors (this distance is based on documentation by the 802.11 standard).
What Is Kismet?
Kismet is an 802.11 wireless network detector, sniffer and intrusion detection system. Kismet will work with any wireless card that supports raw monitoring mode, and it can sniff 802.11b, 802.11a, 802.11g and 802.11n traffic (devices and drivers permitting).
Kismet also sports a plugin architecture allowing for additional non-802.11 protocols to be decoded.
Kismet identifies networks by passively collecting packets and detecting networks, which allows it to detect (and given time, expose the names of) hidden networks and the presence of non-beaconing networks via data traffic.
Kismet has two modes that can be run. The first is the Kismet Server, which the Kismet User Interface (Kismet UI) connects to (Figure 1). The Kismet UI shows the WAP name, if is an access point or not, encrypted or not, the channel and other information. The "seen by" column is the list of capture sources that saw the WAPs.
![]()
Figure 1. Kismet Network List
Kismet calls the remote sensors drones. They're configured through the kismet drone configuration file in /etc/kismet/kismet_drone.conf. I found the documentation for setting up this part rather sparse. Everything I found spanned multiple years and didn't go into too much detail.
When I configured my drones, I set one up first and then cloned the SD card with the
dd command. I copied the cloned image to the other SD cards, again using
dd. To speed up
dd, set the block size to about half the computer's memory.
Making the drones this way did cause a problem with the wireless network cards. Use
ifconfig to see what cards the system lists. As you can see from the screenshot shown in Figure 2, my drone02 has the wireless card listed as wlan1, and it is already in monitor mode. After the drives were all cloned, I just had to go in and make minor configuration changes—besides the wireless card change.
![]()
Figure 2. iconfig Screenshot
The Raspberry Pi uses about 750 mAh, and a 5-volt 1-amp power supply doesn't put enough power out to start the wireless card after the Raspberry Pi is booted. Many of the forums I read said that you need something that puts out 1.5–2.1 amps. I found that plugging in the card first prevents the extra draw, and I didn't have a problem.
In the steps below, if you plug in the Wi-Fi card after booting, you risk a power drop to the Raspberry Pi. The loss of power will crash the RPi, and the SD card could be corrupted.
Configuring the Raspberry Pi with Kali
First, download the Kali Raspberry Pi distro from the Kali Linux Web site.
Copy the image to the SD card with the
dd command or a tool like Win32DiskImage in Windows. This creates a bit-for-bit copy of the image on the SD card. It is similar to burning an ISO to a DVD or CD.
Put the SD card into the RPi. Then, attach the Wi-Fi card you're using to a USB port.
Attach a Cat5, Cat5e or Cat6 cable to the Ethernet port. Wired is used to communicate data to the network to prevent problems with the wireless card in monitor mode.
Plug in the micro USB cable to turn on the RPi. Next,
ssh to the device. You may need to do a port scan with nmap to find the RPi. Alternatively, you can use a monitor and keyboard to access the console directly. Again, have all peripherals plugged in prior to plugging in the power.
The login is "root", and the password is "toor".
Configure the Kismet Drone
Configure eth0 with a static IP address like in the static IP address screenshot (Figure 3). This is done under /etc/network/interfaces.
![]()
Figure 3. Static IP Address Screenshot
Restart the networking with
service networking restartor
reboot. If you connected via SSH, you'll have to reconnect.
Next, edit /etc/kismet/kismet_drone.conf. I have included a screenshot (Figure 4), but below are settings I used, and the fields that need to be changed.
![]()
Figure 4. drone.conf
Set the following either to something that makes sense to you or the right information for your network and device. I used what I have configured for the examples.
Name the drone with
servername. This will show up in the bottom of the Kismet UI and logs when connecting.
Use
dronelisten to set the protocol, interface's IP address and port for the drone is to listen on for servers' connection.
List what servers can talk to this drone with
allowedhosts. This can be a whole network using CIDR notation or just individual boxes on the network, and also allow the drone to talk to itself with
droneallowedhosts.
Set the maximum number of servers that can talk to the drone with
dronemaxclients.
Set the max backlog of packets for the kismet drone with
droneringlen. Smaller than what I have might be better. I had problems with drone04 crashing. It also was the one that saw the most networks.
Turn off GPS with
gps=false. You don't need it since these are stationary devices and you should know where they are.
Set the capture source,
ncsource. This tells the system what interface to use and driver to use for that card:
servername=Kismet-Drone-pi2
dronelisten=tcp://192.168.1.12:2502
allowedhosts=192.168.1.65
droneallowedhosts==127.0.0.1
dronemaxclients=10
droneringlen=65535
gps=false
ncsource=wlan1:type=ath5k
The rest of the options I left set to default. Unless you're in a country that uses more B/G channels than the US, there is nothing that needs to be modified.
The last thing to configure on the drones is the /etc/rc.local file. This will start the kismet drone program in the background when the RPi powers on. Add these two lines before the
exit 0 so yours looks like the code below:
# start kistmet
/usr/bin/kismet_drone --daemonize
exit 0
Configure the Kismet Server on a PC or Server for the Drone Sensors
There are two settings to change in /etc/kismet/kismet.conf. The first is in the
ncsource. The second is the
filter_tracking.
The line below and related screen capture (Figure 5) tell Kismet what its capture sources are. In this case, nothing local is being used, just the drones. Repeat this line for each drone, with the proper information:
ncsource=drone:host=192.168.1.12,port=2502,name=i2 The line says the source is a drone, the drone's IP address, what port to connect to on the drone, and what the drone should show as in the Kismet UI. The name is seen "network list" view and "network detail" view. I went with the two-character name of "i#" because the "Last Seen By" field in the network list has a hard-coded limit of ten characters. I wanted that field to show as many drones as it could.
![]()
Figure 5. Kismet Server Sources
Next, filter out the known network BSSIDs. Previously, I mentioned that a wireless survey or network documentation should be able to provide this information. As you can see in the network list screenshot, several devices are listed. If you have devices you don't want to see, you'll need to filter them out in the Kismet Server configuration file /etc/kismet/kismet.conf.
In the configuration file, it has an example of:
filter_tracker=ANY(!"00:00:DE:AD:BE:EF") In my version of Kismet, that did not work. I had to remove the quotes so the line looked like this:
filter_tracker=BSSID(!00:00:DE:AD:BE:EF) The bang (!) ignores that MAC address. This shows everything but ignored WAPs. Without the bang (!), Kismet would show only the WAP with that BSSID in the network list. The choices are ANY, BSSID, SOURCE and DEST. Although the documentation says you can use ANY with a bang (!), trying it fails. The error said to use one of the other three options. The MAC address can be stacked using a comma-separated list:
filter_tracker=BSSID(!00:00:DE:AD:BE:EF,!00:0:DE:AD:BE:EE, ↪!00:00:DE:AD:BE:ED) With the Drone Sensor Network running, the network detail screen for an access point will show which drones see the WAP (Figure 6). But, this is a limitation of the system. This screen provides only the signal strength for the drone with the strongest signal. This was the limit of Mr Pesce's WRT54GL option.
![]()
Figure 6. Network Detail Screen
In Mr Pesce's model, once the rogue WAP was detected, someone had to go out and search. The search area was around all the drones that saw the rouge WAP. Although his design makes the search area smaller than a whole building, it doesn't triangulate very well. By using the RPis as drones, there is a second program you can use for triangulation.
Airodump-NG, as I mentioned before, is for capturing packets on over Wi-Fi. The user interface, when running Airodump-NG, provides several bits of information. The ones you want are BSSID, PWR (power measured in negative DB), Channel and ESSID (Figures 7–9: each image shows a different power level, which when used with the Roosevelt picture, shows how to use it for triangulation).
![]()
Figure 7. Drone2 airodump
![]()
Figure 8. Drone3 airodump
![]()
Figure 9. Drone4 airodump
ssh to each RPi drone, and run this command. Don't forget to replace the
bssid with the MAC address of the WAP you are looking for and the interface for what that drone is monitoring with:
airodump-ng --bssid Note: I did not use the channel command in the above line to lock a channel. This would interfere with data going back to the Kismet Server and lose the device if the WAP is configured for channel hopping.
Proof of Concept
I did my proof of concept at Eastern Michigan University's Roosevelt Hall, which is where my degree program's labs are. In the map of Roosevelt Hall (Figure 10), there are three drones. This was due to power and Ethernet cable limitations. There is also a rogue WAP (rogue_ap_pi), hidden by my professor. Kismet showed me all the networks in the area, because I didn't have BSSIDs to filter them out. Again, this is where having network documentation or a wireless survey would be helpful.
![]()
Figure 10. Map of Roosevelt Hall at Eastern Michigan University (Google Maps)
Drone3 and drone4 are in a hallway. Drone2 is in one of the lab rooms, with the Linksys network and my laptop running the Kismet Server and Kismet UI. When drone4 was just inside the lab's door, there was a 10DB signal loss. Again, a wireless survey would have helped, because it would show how much signal the walls blocked.
Once I had the system up and running and the drones where I wanted them, my professor hid the rogue WAP somewhere on the same floor. By looking at the power levels, I was able to figure out where to go to find the rouge WAP. I knew that drone4 was the closest and that the rogue WAP was on the other side of that drone. I walked down that hallway and found the rogue WAP in less than two minutes. It was hidden under a bench in the hall, outside a classroom and the other lab.
Limitations of the Wi-Fi Card
The last limitation I want to cover is the TP-Link TL-WN722N card. I went with this card because of the cost, the external antenna, the power draw when plugged in to the RPi and its availability at a local store. The card can talk only on the 2.4GHz range, meaning that it picks up only 802.11 B, G and N networks. It does not have the ability to detect or use the 5GHz range used by parts of N, A or the new AC networks.
Although I have a couple ALFA wireless cards, and one that should be able to detect A and AC, I do not know if I could run them on the RPi drone without a separate powered USB hub.
This setup also does not detect Zigbee/Xbee or Bluetooth. Xbee uses both 900MHz and 2.4GHz.
Bluetooth uses 2.4GHz. Although both devices use 2.4GHz, frequencies (channels) are outside the Wi-Fi card's range. Mike Kershaw (aka Dragorn, Kismet's developer) is working on a hardware and software Xbee detector called kisbee. An Ubertooth One should work with Kismet to detect Bluetooth.
Cell phones and related cellular network cards also would be missed. Phones operate outside the Wi-Fi card's range, unless the phone is a Wi-Fi hotspot. The new HackRF One card might be able to detect the cellular networks, as well as A/B/G/N/AC Wi-Fi, Xbee and Bluetooth, but I haven't gotten one to play with, and they would drive up the cost to about $300 USD per sensor.
Resources
Kismet:
http://kismetwireless.net Kali Linux:
http://www.kali.org




















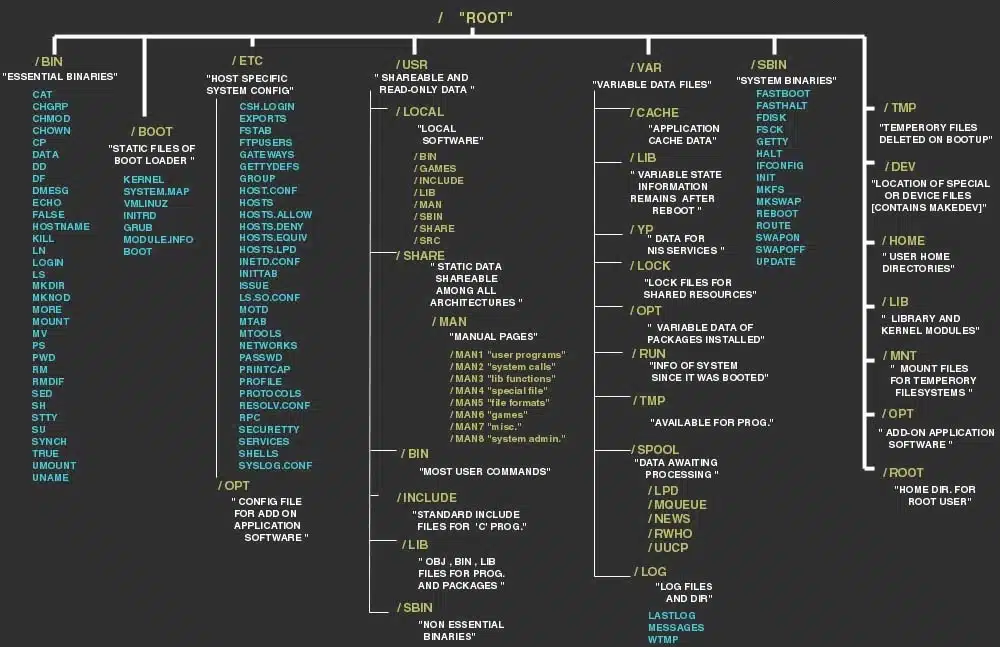
 Figure 1. Kismet Network List
Figure 1. Kismet Network List  Figure 2. iconfig Screenshot
Figure 2. iconfig Screenshot  Figure 3. Static IP Address Screenshot
Figure 3. Static IP Address Screenshot  Figure 4. drone.conf
Figure 4. drone.conf  Figure 5. Kismet Server Sources
Figure 5. Kismet Server Sources  Figure 6. Network Detail Screen
Figure 6. Network Detail Screen  Figure 7. Drone2 airodump
Figure 7. Drone2 airodump  Figure 8. Drone3 airodump
Figure 8. Drone3 airodump  Figure 9. Drone4 airodump
Figure 9. Drone4 airodump  Figure 10. Map of Roosevelt Hall at Eastern Michigan University (Google Maps)
Figure 10. Map of Roosevelt Hall at Eastern Michigan University (Google Maps)