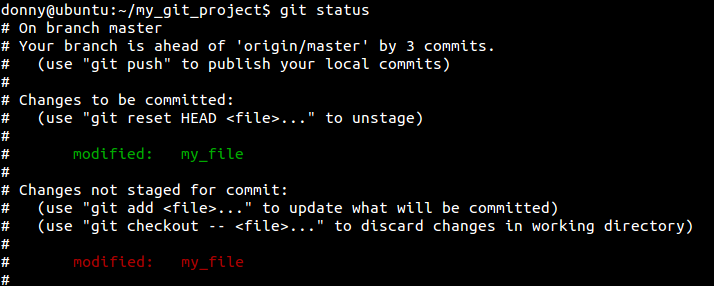
By establishing a connection to an
OpenVPN server, we basically create a secure communications channel between our device and the remote host OpenVPN runs on. Although traffic flowing between these two end-points can be intercepted, it is strongly encrypted and thus practically useless to the interceptor. In addition to the OpenVPN acting as the facilitator of this encrypted channel (or tunnel), we may configure the server to also play the role of our Internet gateway. By doing so, we can for example hook up to any open, inherently insecure WiFi network, then immediately connect to the remote OpenVPN server and start using any Internet-enabled application without worrying of prying eyes or bored administrators. (Note though that we still need to trust any administrator in the vicinity of the OpenVPN server. But more on that towards the end of the post.)
This article is a step-by-step guide on how to setup OpenVPN on
Ubuntu Server 14.04 LTS. The OpenVPN host computer may be a VPS in the cloud, a virtual machine running on one of our computers at home, or even that somewhat aged box we tend to forget we have.
Step 01 -- System Preparation
We gain access to a command shell in the Ubuntu Server host, for example by remotely connecting to it via SSH, and immediately refresh the local repository database:
sub0@delta:~$ sudoapt-get update
|
To perform any upgrades for all installed packages and the operating system itself, we type:
sub0@delta:~$ sudoapt-get dist-upgrade
|
If a new kernel gets pulled in, a system reboot will be required. After refreshing and upgrading, it’s time to install OpenVPN:
sub0@delta:~$ sudoapt-get -y installopenvpn easy-rsa dnsmasq
|
Notice that we installed three packages with apt-get:
- openvpn provides the core of OpenVPN
- easy-rsa contains some handy scripts for key management
- dnsmasq is the name server we’ll be using later on, when our OpenVPN server box/VM will assume the role of a router for all OpenVPN clients
Step 02 -- Master certificate and private key for the Certificate Authority
The most important –and admittedly the most crucial– step during the setup of an OpenVPN server, is the establishment of a corresponding Public Key Infrastructure (PKI). This infrastructure comprises the following:
- A certificate (public key) and a private key for the OpenVPN server
- A certificate and a private key for any OpenVPN client
- A master certificate and a private key for the Certificate Authority (CA). This private key is used for signing the OpenVPN certificate as well as the client certificates.
Beginning with the latter, we create a convenient working directory
sub0@delta:~$ sudomkdir/etc/openvpn/easy-rsa
|
and then copy easy-rsa’s files to it:
sub0@delta:~$ sudocp-r /usr/share/easy-rsa/* /etc/openvpn/easy-rsa
|
Before we actually create the keys for the CA, we open /etc/openvpn/easy-rsa/vars for editing (we like the nano text editor but this is just our preference):
sub0@delta:~$ sudonano /etc/openvpn/easy-rsa/vars
|
Towards the end of the file we assign values to a set of variables which are read during the creation of the master certificate and private key. Take a look at the variables we assigned values to:
export KEY_COUNTRY="GR"
export KEY_PROVINCE="Central Macedonia"
export KEY_CITY="Thessaloniki"
export KEY_ORG="Parabing Creations"
export KEY_EMAIL="nobody@parabing.com"
export KEY_CN="VPNsRUS"
export KEY_NAME="VPNsRUS"
export KEY_OU="Parabing"
export KEY_ALTNAMES="VPNsRUS"
|
It goes without saying that you may assign different values, more appropriate for your case. Also take particular note of the last line, in which we set a value to the KEY_ALTNAMES variable. This line is not part of the original vars file but we nevertheless append it at the end of said file, or the build-ca script we’re going to run next will fail.
To save the changes in vars we hit [CTRL+O] followed by the [Enter] key. To quit nano we hit [CTRL+X]. Now, we gain access to the root account and move on to building of the master certificate and private key:
sub0@delta:~$ sudosu
root@delta:/home/sub0
root@delta:/etc/openvpn/easy-rsa
NOTE: If you run ./clean-all, I will be doing a rm-rf on /etc/openvpn/easy-rsa/keys
root@delta:/etc/openvpn/easy-rsa
root@delta:/etc/openvpn/easy-rsa
Generating a 1024 bit RSA private key
...++++++
................++++++
writing new private key to 'ca.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [GR]:
State or Province Name (full name) [Central Macedonia]:
Locality Name (eg, city) [Thessaloniki]:
Organization Name (eg, company) [Parabing Creations]:
Organizational Unit Name (eg, section) [Parabing]:
Common Name (eg, your name or your server's hostname) [VPNsRUS]:
Name [VPNsRUS]:
Email Address [nobody@parabing.com]:
root@delta:/etc/openvpn/easy-rsa
|
In our example the default answers were used for all the questions. After the build-ca script finishes we have the file for the master certificate (keys/ca.crt) and also the file for the private key (keys/ca.key). The latter must be kept secret at all costs.
Step 03 -- Certificate and private key for the OpenVPN server
Before we make a certificate and private key for our OpenVPN server, we need to pick a name for it. We decided to name ours “delta” and then ran the build-key-server script to get the keys:
root@delta:/etc/openvpn/easy-rsa
Generating a 1024 bit RSA private key
....++++++
...++++++
writing new private key to 'delta.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [GR]:
State or Province Name (full name) [Central Macedonia]:
Locality Name (eg, city) [Thessaloniki]:
Organization Name (eg, company) [Parabing Creations]:
Organizational Unit Name (eg, section) [Parabing]:
Common Name (eg, your name or your server's hostname) [delta]:
Name [VPNsRUS]:deltaVPN
Email Address [nobody@parabing.com]:
Please enter the following 'extra'attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
Using configuration from /etc/openvpn/easy-rsa/openssl-1.0.0.cnf
Check that the request matches the signature
Signature ok
The Subject's Distinguished Name is as follows
countryName :PRINTABLE:'GR'
stateOrProvinceName :PRINTABLE:'Central Macedonia'
localityName :PRINTABLE:'Thessaloniki'
organizationName :PRINTABLE:'Parabing Creations'
organizationalUnitName:PRINTABLE:'Parabing'
commonName :PRINTABLE:'delta'
name :PRINTABLE:'deltaVPN'
emailAddress :IA5STRING:'nobody@parabing.com'
Certificate is to be certified untilApr 7 08:06:02 2024 GMT (3650 days)
Sign the certificate? [y/n]:y
1 out of 1 certificate requests certified, commit? [y/n]y
Write out database with 1 new entries
Data Base Updated
root@delta:/etc/openvpn/easy-rsa
|
The script successfully finished and we got a certificate (keys/delta.crt) as well as a private key (keys/delta.key) for our server. Note that the server certificate is signed by the CA’s private key.
Step 04 -- Diffie-Hellman parameters
The secure passing of keys over an insecure communications channel is made possible thanks to a well-known technique involving the so called Diffie-Hellman parameters. To generate those we just type
root@delta:/etc/openvpn/easy-rsa
Generating DH parameters, 2048 bit long safe prime, generator 2
This is going to take a long time
.......................+.....................................+..
...........................+..+.....................+...........
..............................................+.................
.......................+........................................
................................................+...............
.......................................++*++*++*
root@delta:/etc/openvpn/easy-rsa
|
The certificates, private keys and the file containing the Diffie-Hellman parameters we just generated, are all stored into the /etc/openvpn/easy-rsa/keys directory. So up until now we have five files in total and in our case they are as follows:
- ca.crt– the certificate of the Certificate Authority
- ca.key– the private key of the CA
- delta.crt– the certificate of the OpenVPN server
- delta.key– the private key of the OpenVPN server
- dh2048.pem– the Diffie-Hellman parameters file
In all likelihood, the keys for your own OpenVPN server are named differently. We now need to copy all files but the ca.key over to the /etc/openvpn directory:
root@delta:/etc/openvpn/easy-rsa
root@delta:/etc/openvpn/easy-rsa/keys
root@delta:/etc/openvpn/easy-rsa/keys
root@delta:/etc/openvpn/easy-rsa
|
Step 05 -- Certificates and private keys for the OpenVPN clients
Let’s assume we’d like to connect to the OpenVPN server from our laptop. That’s actually a very common scenario and in order to be able to do so we first need to generate a certificate as well as a private key for the client, i.e. our laptop. There’s a script for that and it lives in the /etc/openvpn/easy-rsa directory:
root@delta:/etc/openvpn/easy-rsa
NOTE: If you run ./clean-all, I will be doing a rm-rf on /etc/openvpn/easy-rsa/keys
root@delta:/etc/openvpn/easy-rsa
Generating a 1024 bit RSA private key
.......................................++++++
...................................................................................................++++++
writing new private key to 'laptop.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [GR]:
State or Province Name (full name) [Central Macedonia]:
Locality Name (eg, city) [Thessaloniki]:
Organization Name (eg, company) [Parabing Creations]:
Organizational Unit Name (eg, section) [Parabing]:
Common Name (eg, your name or your server's hostname) [laptop]:
Name [VPNsRUS]:
Email Address [nobody@parabing.com]:
Please enter the following 'extra'attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
Using configuration from /etc/openvpn/easy-rsa/openssl-1.0.0.cnf
Check that the request matches the signature
Signature ok
The Subject's Distinguished Name is as follows
countryName :PRINTABLE:'GR'
stateOrProvinceName :PRINTABLE:'Central Macedonia'
localityName :PRINTABLE:'Thessaloniki'
organizationName :PRINTABLE:'Parabing Creations'
organizationalUnitName:PRINTABLE:'Parabing'
commonName :PRINTABLE:'laptop'
name :PRINTABLE:'VPNsRUS'
emailAddress :IA5STRING:'nobody@parabing.com'
Certificate is to be certified untilApr 7 18:00:51 2024 GMT (3650 days)
Sign the certificate? [y/n]:y
1 out of 1 certificate requests certified, commit? [y/n]y
Write out database with 1 new entries
Data Base Updated
root@delta:/etc/openvpn/easy-rsa
|
The base name we chose for the keys was “laptop”, so after the build-key finished we got keys/laptop.crt (certificate) and keys/laptop.key (private key). Those two keys for the particular client along with the CA’s certificate file go together, and it’s a good idea to copy them to a directory where our user (sub0) has full access to. We can, for example, create a new directory in the user’s home directory and copy those three files there:
root@delta:/etc/openvpn/easy-rsa
root@delta:/etc/openvpn/easy-rsa
root@delta:/etc/openvpn/easy-rsa/keys
root@delta:/etc/openvpn/easy-rsa/keys
root@delta:/etc/openvpn/easy-rsa/keys
root@delta:/etc/openvpn/easy-rsa
|
The directory ovpn-client must be securely copied to our laptop. We are allowed to distribute those three files to more than one clients, as long as they are all ours. Of course, should we need a different certificate-private key couple, we run the build-key script again.
Step 06 -- OpenVPN server configuration
In a little while our OpenVPN server will be up and running. But first, there are some configuration changes that need to be made. There’s a sample configuration file in /usr/share/doc/openvpn/examples/sample-config-files which is excellent for our setup. That file is named server.conf.gz:
root@delta:/etc/openvpn/easy-rsa
root@delta:/etc/openvpn
root@delta:/etc/openvpn
root@delta:/etc/openvpn
root@delta:/etc/openvpn
|
As you can see, we copied server.conf.gz into the /etc/openvpn directory, uncompressed it and renamed it to delta.conf. You may choose any name you like for your OpenVPN server’s configuration file, as long as it has the “.conf” extension. Whatever the base name, we now open the configuration file with nano:
Here are the changes and additions we should make.
- First, we locate the lines
cert server.crt
key server.key
|
cert delta.crt
key delta.key
|
- We locate the lineand replace “1024″ with “2048″:
- At the end of the configuration file we add the following two lines:
push "redirect-gateway def1"
push "dhcp-option DNS 10.8.0.1"
|
Those last two lines instruct the clients to use OpenVPN as the default gateway to the Internet, and also use 10.8.0.1 as the server to deal with DNS requests. Notice that 10.8.0.1 is the IP address of the tunnel network interface OpenVPN automatically creates upon startup. If the clients were to use any other server for name resolution, then we would have a situation in which all DNS requests were served from a possibly untrustworthy server. To avoid such DNS leaks, we instruct all OpenVPN clients to use 10.8.0.1 as the DNS server.
We start our OpenVPN server like this:
By default, OpenVPN listens for connections on port 1194/UDP. One way to see that is with the netstat tool:
root@delta:/etc/openvpn
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Programname
udp 0 0 0.0.0.0:54149 0.0.0.0:* 555/dhclient
udp 0 0 0.0.0.0:1194 0.0.0.0:* 3024/openvpn
udp 0 0 0.0.0.0:53 0.0.0.0:* 2756/dnsmasq
udp 0 0 0.0.0.0:68 0.0.0.0:* 555/dhclient
udp6 0 0 :::60622 :::* 555/dhclient
udp6 0 0 :::53 :::* 2756/dnsmasq
|
All is well, though we have no properly configured DNS server for the clients yet.
Step 07 -- A DNS service for OpenVPN clients
That’s why we’ve installed dnsmasq for. We open up its configuration file
locate this line
and change it into the following one:
listen-address=127.0.0.1, 10.8.0.1
|
We also locate this line
and delete the hash character on the left:
To make dnsmasq take these changes into account, we just restart the service:
root@delta:/etc/openvpn
* Restarting DNS forwarder and DHCP server dnsmasq [ OK ]
root@delta:/etc/openvpn
|
As it is now, dnsmasq listens for DNS requests from the loopback (lo) and also from the tunnel (tun0) interface. The output of netstat confirms that:
root@delta:/etc/openvpn
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Programname
udp 0 0 0.0.0.0:57219 0.0.0.0:* 638/dhclient
udp 0 0 0.0.0.0:1194 0.0.0.0:* 911/openvpn
udp 0 0 127.0.0.1:53 0.0.0.0:* 1385/dnsmasq
udp 0 0 10.8.0.1:53 0.0.0.0:* 1385/dnsmasq
udp 0 0 0.0.0.0:68 0.0.0.0:* 638/dhclient
udp6 0 0 :::39148 :::* 638/dhclient
|
Step 08 -- Router functionality
We want the VM/box our OpenVPN server runs on to behave like a router, and that means that IP forwarding must be enabled. To enable it right now, from the root account we just type
To make this setting persistent across reboots we open up /etc/sysctl.conf
locate the line
and remove the hash character on the left:
There are also some iptables-related rules we should activate:
root@delta:/etc/openvpn
root@delta:/etc/openvpn
root@delta:/etc/openvpn
root@delta:/etc/openvpn
root@delta:/etc/openvpn
|
And of course we want these rules activated every time Ubuntu boots up, so we add them inside /etc/rc.local:
#!/bin/sh -e
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
# Make sure that the script will "exit 0" on success or any other
# value on error.
#
# In order to enable or disable this script just change the execution
# bits.
#
# By default this script does nothing.
iptables -A FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT
iptables -A FORWARD -s 10.8.0.0/24 -j ACCEPT
iptables -A FORWARD -j REJECT
iptables -t nat -A POSTROUTING -s 10.8.0.0/24 -o eth0 -j MASQUERADE
service dnsmasq restart
exit 0
|
Please notice the line before the last one:
This is crucial: During system startup dnsmasq tries to come up before OpenVPN does. But without OpenVPN there is no tunnel interface (tun0) present so naturally dnsmasq fails. A bit later, when /etc/rc.local is read the tun0 interface is present, so at this point we restart dnsmasq and everything is as it's supposed to be.
Step 09 -- Client configuration
In Step 05 we created the directory ovpn-client inside our user’s home directory (/home/sub0, in our example). In there we have the CA certificate plus the client certificate and private key. There’s only one file missing and that’s the configuration file for the client. A sample file we can use is inside /usr/share/doc/openvpn/examples/sample-config-files:
root@delta:/etc/openvpn
exit
sub0@delta:~$ cd~/ovpn-client
sub0@delta:~/ovpn-client$ cp/usr/share/doc/openvpn/examples/sample-config-files/client.conf .
sub0@delta:~/ovpn-client$
|
We open up client.conf for editing and immediately locate the following line:
This “my-server-1″ string is a placeholder and we are now going to replace it for our server’s public domain name or public IP. If we do have a public domain name already assigned to the server, then there’s nothing more to do than put it in place of my-server-1. Things get a tiny bit more involved if there’s no public domain name for our server. What’s the public IP for it? One way to find out is by typing the following:
sub0@delta:~/ovpn-client$ curl ipecho.net/plain; echo
|
(If instead of a numeric IP address you get an error, just wait a few seconds and try again.) So now we know our server’s public IP, but is it static or dynamic? Well, if we’re dealing with a server at home or even at the office, chances are it has a dynamic IP address. In that case it is advisable to use a free dynamic DNS service, such as the one provided by http://www.noip.com. In the case of NoIP, assuming we have chosen the free domain dnsalias.net then we may end up with a line like this
remote ovpn.dnsalias.net 1194
|
where “ovpn” is the hostname we’ve given to the server. On the other hand, if our server is hosted in the cloud then it probably has a static public IP address. In that case, the remote directive inside client.conf will look like the following:
There are two more lines we need to modify:
cert client.crt
key client.key
|
In our case, the certificate and private key files for the client are named laptop.crt and laptop.key respectively, so our client.conf contains these two lines:
cert laptop.crt
key laptop.key
|
After making sure the changes to client.conf are saved, we need to securely transfer the whole ovpn-client directory to the client. One way to do so is by using the scp command (secure copy or copy over SSH). An alternative is provided by the excellent and free FileZilla, which supports FTP over SSH connections (SFTP).
Step 10 -- Connecting and testing
![In front of any instance our IaaS provider has a firewall in place, so in order for our OpenVPN server to be reachable from the Internet we explicitly open port 1194/UDP.]()
So how do we actually connect to the remote OpenVPN server? It all depends on the type of the device we have in hand and of course on the operating system is runs. In a bit we are going to examine the cases of four different OS families — or OS categories, if you will: Linux, Windows, OS X and iOS/Android. Note though that no matter the device or the OS, for the connection to be successful we need to be outside of the OpenVPN server’s local network. In addition, if there’s a firewall in front of the server –and it probably is– then we ought to put a new rule in place which essentially states something like this:
Redirect all incoming UDP packets for port 1194 to port 1194/UDP of the server’s public-facing network interface.That’s some simple firewall rule, don’t you think? And without further ado, let’s establish our first connection to the fabulous OpenVPN server of ours.
Linux. All we need is the openvpn package installed. One way to connect to the remote OpenVPN server is to fire up a terminal, change to the ovpn-client directory and from the root user account –or with the assistance of sudo– type something like this:
/usr/sbin/openvpn--config client.conf
|
Anytime we want to terminate the connection we just hit [CTRL+C].
Windows. A free OpenVPN client is the so called
OpenVPN Desktop Client. The configuration file client.conf must be renamed to client.ovpn and that’s the file we should give to the OpenVPN Desktop Client. The application will read client.ovpn and create a new connection profile for the OpenVPN server.
![Is the WiFi hotspot we're connected to secure? Thanks to OpenVPN we can say ‘don't know, don't care’ -- and really mean it. In this example we use our favorite OpenVPN client for our favorite OS to establish a secure, encrypted communications channel with a remote OpenVPN server, in a datacenter somewhere outside the capital of our favorite country in the world :)]() OS X.
OS X. A free OpenVPN client for OS X is
tunnelblick. There is also
Viscosity which is commercial and happens to be our favorite. Viscosity will read client.conf and create a new connection profile for the remote server.
iOS/Android. An excellent choice is OpenVPN connect. It is free of charge and available from the
App Store as well as the Google
Play store.
Regardless of the computing platform, sometimes we’d like to check if we’re actually using the OpenVPN server we think we’re using. One way to do that is by following this simple 4-step procedure:
Prior to connecting to the OpenVPN server we…
- visit a site such as whatip.com and take note of our public IP
- visit dnsleaktest.com, perform the standard test, take note of the name servers we’re using
![What's the DNS server we're currently using? Well, its IP address is 10.8.0.1 and in this particular case that means all our DNS requests are routed through a secure, encrypted tunnel. In not-so-many words, there are no DNS leaks to worry about.]()
After connecting to the OpenVPN server we repeat the above two steps. If we get two different public IPs, this means we do go out on the net through the remote OpenVPN server. In addition, if we get two different sets of name servers, then there are no DNS leaks.
Final thoughts
I use three different OpenVPN servers, all custom-made. One of them runs on the pfSense router at my home office in Thessaloniki, Greece. I use this server when I’m out of office and want secure access to the home LAN. The other two OpenVPN servers are hosted on two different VPSes, one in Reykjavik, Iceland, and the other in New Jersey, USA. Whenever I’m out and about and feel like using a random WiFi hotspot, I don’t even have to think of the security implications: I simply connect to the Reykjavik server and start surfing the web normally. There are also some times when I want to casually check out a service which is geographically restricted to the US. In these not-so-common cases the New Jersey server comes in handy, for when I connect to it I get a public IP from the U, S of A and hence access to that otherwise restricted service. It is worth noting that some service providers maintain blacklists with numerous well-known VPN companies. And that’s *exactly* one of the advantages of setting up your own OpenVPN server on a VPS provider of your choosing: It’s unlikely that this provider is blacklisted.
No matter where the physical location of your server is, OpenVPN ensures that the traffic flow between the client and the server is strongly encrypted. What happens to the traffic leaving the OpenVPN server is another story. Depending on the application-layer protocol it may still be encrypted, but it could be unencrypted as well. So unless you have absolute control of the OpenVPN server and of the local network it belongs to, you cannot fully trust the administrator at the other end. The moral of this is apparent: If you really care about your privacy, then you should keep in mind that your own behavior may indeed undermine it.
One example will hopefully get the point across. You have a well configured OpenVPN server in the cloud. You use any random WiFi hotspot anytime you feel like it and without the slightest bit of worry, thanks to that heroic OpenVPN server. Then you fire up your favorite mail client to get your email from this good, old mail server which still uses plain SMTP. Guess what? Your username and password leave the OpenVPN server in plain text, i.e. unencrypted. At the same time a bored administrator in the vicinity of the OpenVPN server could be easily sniffing-out your credentials and storing them in their ever-growing list named “random happy people.txt”.
So what do you do? Simple. You continue using your OpenVPN server, but refrain from using applications which talk old and/or insecure protocols.
Enjoy your brand new OpenVPN server!





















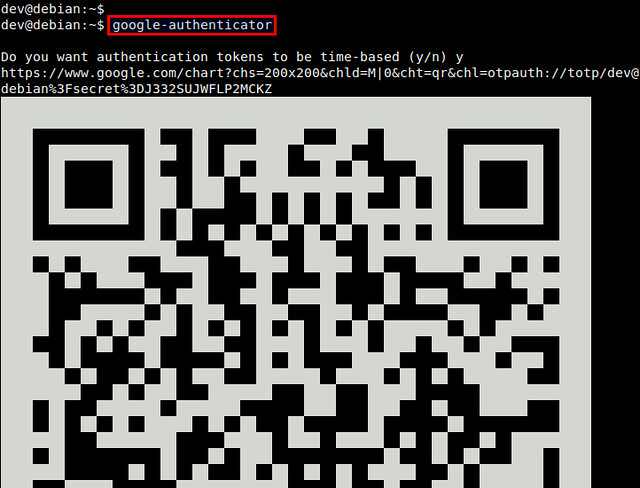
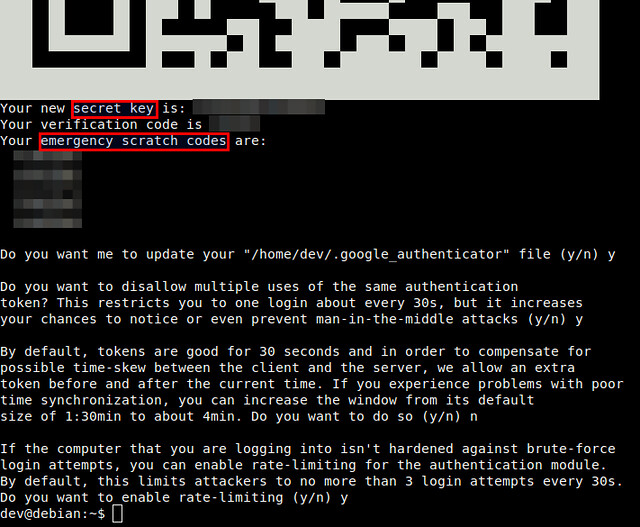
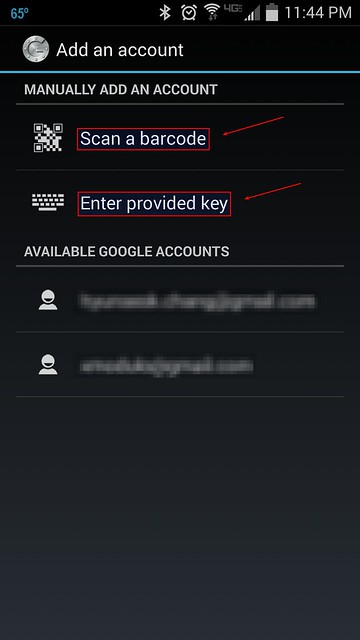
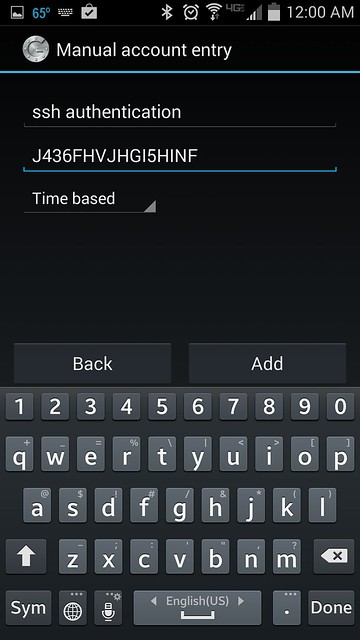



 Georgia Tech
Georgia Tech










