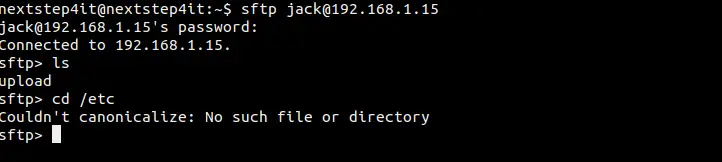
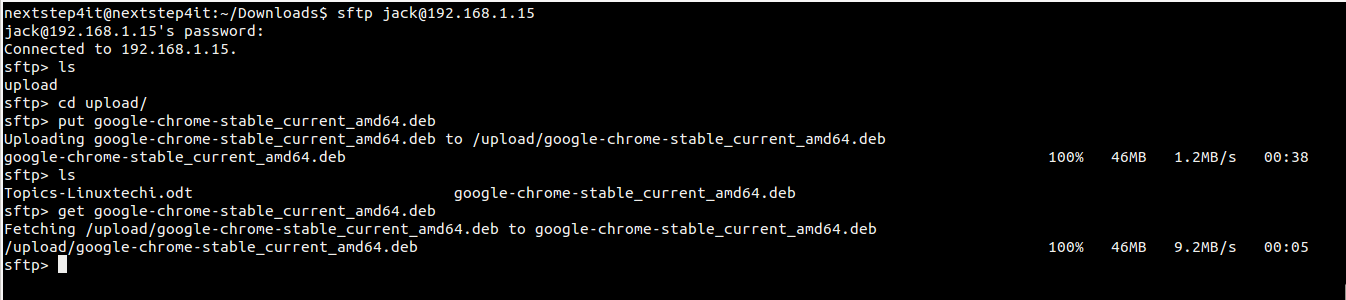
We’re not about to reiterate the valid concerns of privacy and/or anonymity minded people. Instead, we are going to demonstrate how one can make a small but extremely significant contribution towards an Internet where anonymity is an everyday practical option and not an elusive goal. (If you’re also interested in privacy, then maybe it’s time to setup
your very own OpenVPN server.)
You’ve probably heard about
Tor. Technically speaking, it is a global mesh of nodes, also known as relays, which encrypt and bounce traffic between client computers and servers on the Internet. That encryption and bouncing of traffic is done in such a way, that it is practically impossible to know who visited a web site or used a network service in general. To put it simply, anytime I choose to surf the web using Tor it’s impossible for the administrators of the sites I visit to know my real IP address. Even if they get subpoenaed, they are just unable to provide the real addresses of the clients who reached them through Tor.
If you care about your anonymity or you’re just curious about Tor, then you may easily experience it by downloading the official, freely available
Tor Browser Bundle. The effectiveness of Tor relies in the network of those aforementioned relays: The more active relays participate in the Tor network, the stronger the anonymity Tor clients enjoy is.
It is relatively easy to contribute to the strengthening of the Tor network. All you really need is an active Internet connection and a box/VM/VPS — or even a cheap computer like the
Raspberry Pi. In the remainder of this post we demonstrate how one can setup a Tor relay on a VPS running
Ubuntu Server 14.04 LTS (Trusty Tahr). You may follow our example to the letter or install Tor on some different kind of host, possibly running some other Linux distribution, flavor of BSD, OS X or even Windows.
Installation
We SSH into our Ubuntu VPS, gain access to the root account and add to the system a new, always up-to-date Tor repository:
$ sudo su
# echo "deb http://deb.torproject.org/torproject.org trusty main">> /etc/apt/sources.list
|
If you’re not running the latest version of Ubuntu Server (14.04 LTS, at the time of this writing), then you should replace “trusty” with the corresponding codename. One way to find out the codename of your particular Ubuntu version is with the help of lsb_release utility:
# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 14.04 LTS
Release: 14.04
Codename: trusty
|
Now, let’s refresh all the local repositories:
# apt-get update
...
W: GPG error: http://deb.torproject.org trusty InRelease:
The following signatures couldn't be verified because the
public key is not available: NO_PUBKEY
|
The Tor repository signature cannot be verified, so naturally we get an error. The verification fails because the public key is missing. We may manually download that key and let APT know about it, but it’s better to install the deb.torproject.org-keyring package instead. That way, whenever the signing key changes, we won’t have to re-download the corresponding public key.
# apt-get install deb.torproject.org-keyring
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
deb.torproject.org-keyring
0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
Need to get 4138 B of archives.
After this operation, 20.5 kB of additional disk space will be used.
WARNING: The following packages cannot be authenticated!
deb.torproject.org-keyring
Install these packages without verification? [y/N] y
|
We confirm the installation of deb.torproject.org-keyring and then refresh the local repositories:
This time around there should be no errors. To install Tor itself, we just have to type…
# apt-get install tor
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following extra packages will be installed:
tor-geoipdb torsocks
Suggested packages:
mixmaster xul-ext-torbutton socat tor-arm polipo privoxy apparmor-utils
The following NEW packages will be installed:
tor tor-geoipdb torsocks
0 upgraded, 3 newly installed, 0 to remove and 0 not upgraded.
Need to get 1317 kB of archives.
After this operation, 5868 kB of additional disk space will be used.
Do you want to continue? [Y/n]y
|
That’s all great! By now, Tor should be up and running:
# netstat -antp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 808/sshd
tcp 0 0 127.0.0.1:9050 0.0.0.0:* LISTEN 973/tor
tcp 0 0 10.10.10.235:22 10.10.10.250:49525 ESTABLISHED 2095/sshd: sub0
tcp6 0 0 :::22 :::* LISTEN 808/sshd
|
But before we add a new relay to the Tor network, we should properly configure it first.
Configuration
The Tor configuration file is named torrc and it resides within the /etc/tor directory. Before we make any changes to it, it’s a good idea to keep a backup. Then we open up torrc with a text editor, e.g., nano:
# cp /etc/tor/torrc /etc/tor/torrc.original
# nano /etc/tor/torrc
|
We locate the following lines and modify them to fit our setup. Please take a closer look at our modifications:
SocksPort 0
Log notice file /var/log/tor/notices.log
Nickname parabing
ORPort 9001
DirPort 9030
Address noname.example.com # this is optional
ContactInfo cvarelas AT gmail DOT com
RelayBandwidthRate 128 KB
RelayBandwidthBurst 192 KB
ExitPolicy reject *:*
|
Some explaining is in order.
- SocksPort 0
We want Tor to act as a relay only and ignore connections from local applications. - Log notice file /var/log/tor/notices.log
All messages of level “notice” and above should go to /var/log/tor/notices.log. Check the five available message levels here. - Nickname parabing
A name for our Tor relay. Feel free to name yours anyway you like. The relay will be searchable in the various public relay databases by that name. - ORPort 9001
This is the standard Tor port for incoming network connections. - DirPort 9030
This is the standard port for distributing information about the public Tor directory. - Address noname.example.com
This is optional but in some cases useful. If your relay has trouble participating in the Tor network during startup, then try providing here the fully qualified domain name or the public IP address of the host computer/VM/VPS. - ContactInfo cvarelas AT gmail DOT com
You may type a real email address here — and you don’t have to care for syntax correctness: The address may be just intelligible, so if anyone wishes to contact you for any reason then he or she will have a chance to know an email of yours by looking up your relay in a public directory. - RelayBandwidthRate 128 KB
The allowed bandwidth for incoming traffic. In this example it’s 128 kilobytes per second, that is 8 x 128 = 1024Kbps or 1Mbps. Please note that RelayBandwidthRate must be at least 20 kilobytes per second. - RelayBandwidthBurst 192 KB
This is the allowed bandwidth burst for incoming traffic. In our example it’s 50% more than the allowed RelayBandwidthRate. - ExitPolicy reject *:*
This relay does not allow exits to the “normal” Internet — it’s just a member of the Tor network. If you’re hosting the relay yourself at home, then it’s highly recommended to disallow exits. This is true even if you’re running Tor on a VPS. See the Closing comments section for more on when it is indeed safe to allow exits to the Internet.
After all those modifications in /etc/tor/torrc we’re ready to restart Tor (it was automatically activated immediately after the installation). But before we do that, there might be a couple of things we should take care of.
Port forwarding and firewalls
It’s likely that the box/VM/VPS our Tor relay is hosted is protected by some sort of firewall. If this is indeed the case, then we should make sure that the TCP ports for ORPort and DirPort are open. For example, one of our Tor relays lives on a
GreenQloud instance and that particular IaaS provider places a firewall in front of any VPS (instance). That’s why we had to manually open ports 9001/TCP and 9030/TCP on the firewall of that instance. There’s also the case of the ubiquitous residential NAT router. In this extremely common scenario we have to add two port forwarding rules to the ruleset of the router, like the following:
- redirect all incoming TCP packets for port 9001 to port 9001 on the host with IP a.b.c.d
- redirect all incoming TCP packets for port 9030 to port 9030 on the host with IP a.b.c.d
where
a.b.c.d is the IP address of the relay host’s Internet-facing network adapter.
First-time startup and checks
To let Tor know about the fresh modifications in /etc/tor/torrc, we simply restart it:
# service tor restart
* Stopping tor daemon...
* ...
* Starting tor daemon... [ OK ]
#
|
To see what’s going on during Tor startup, we take a look at the log file:
# tail -f /var/log/tor/notices.log
Jul 18 09:30:07.000 [notice] Bootstrapped 80%: Connecting to the Tor network.
Jul 18 09:30:07.000 [notice] Guessed our IP address as 37.b.c.d (source: 193.23.244.244).
Jul 18 09:30:08.000 [notice] Bootstrapped 85%: Finishing handshake with first hop.
Jul 18 09:30:09.000 [notice] Bootstrapped 90%: Establishing a Tor circuit.
Jul 18 09:30:09.000 [notice] Tor has successfully opened a circuit. Looks like client functionality is working.
Jul 18 09:30:09.000 [notice] Bootstrapped 100%: Done.
Jul 18 09:30:09.000 [notice] Now checking whether ORPort 37.b.c.d:9001 and DirPort 37.b.c.d:9030 are reachable... (this may take up to 20 minutes -- look for log messages indicating success)
Jul 18 09:30:10.000 [notice] Self-testing indicates your DirPort is reachable from the outside. Excellent.
Jul 18 09:30:11.000 [notice] Self-testing indicates your ORPort is reachable from the outside. Excellent. Publishing server descriptor.
Jul 18 09:31:43.000 [notice] Performing bandwidth self-test...done.
|
(Press [CTR+C] to stop viewing the log file.) Notice that DirPort and ORPort are reachable — and that’s good. If any of those ports is not reachable, then check the firewall/port forwarding rules. You may also have to activate the Address directive in /etc/tor/torrc and restart the tor service.
![You can look up any Tor relay in the Atlas directory. The relay shown on the screenshot is one of our own and it lives in a datacenter in Iceland, a country with strong pro-privacy laws.]()
Relay monitoring
One way to find out if your new, shiny Tor relay is actually active, is to look it up on
Atlas. You may also monitor its operation in real-time with arm (
anonymizing relay monitor). Before we install arm, let’s make a couple of modifications to /etc/tor/torrc. At first we locate the following two lines and uncomment them (i.e., delete the # character on the left):
ControlPort 9051
HashedControlPassword ...
|
We then move at the end of torrc and add this line:
DisableDebuggerAttachment 0
|
We make sure the modifications to torrc are saved and then restart tor:
To install arm we type:
# apt-get install tor-arm
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following extra packages will be installed:
python-geoip python-socksipy python-support python-torctl
The following NEW packages will be installed:
python-geoip python-socksipy python-support python-torctl tor-arm
0 upgraded, 5 newly installed, 0 to remove and 0 not upgraded.
Need to get 406 kB of archives.
After this operation, 1,735 kB of additional disk space will be used.
Do you want to continue? [Y/n] y
|
There’s no need to work from the root account anymore, so let’s exit to our non-privileged user account:
Right after the installation of the tor-arm package, a new account is created. The username of that account is debian-tor and for security reasons we run arm from the confines of said account:
Closing comments
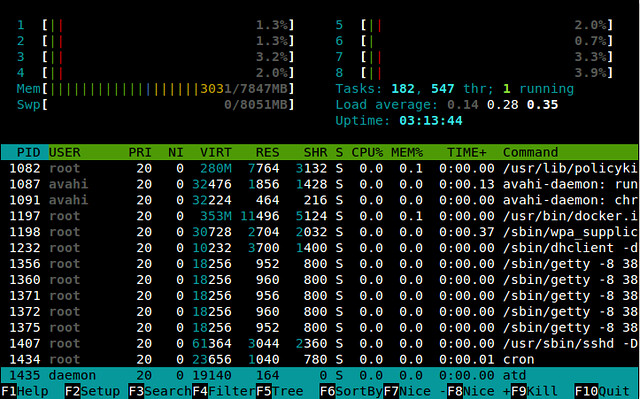
If you have more than one relays running, then no matter if they reside in the same local network or not you may want to put them in the same family, so clients will be able to avoid using more than one of your relays in a single circuit. To do that, on each node open up /etc/tor/torrc for editing, locate and uncomment the MyFamily directive and list the fingerprints of all your relays. One way to find the fingerprint of a relay is to look it up in Atlas; just search for the relay by name, click on the name and take a look at the Properties column. Another way is to simply run arm and check the information at the fourth line from the top of the terminal.
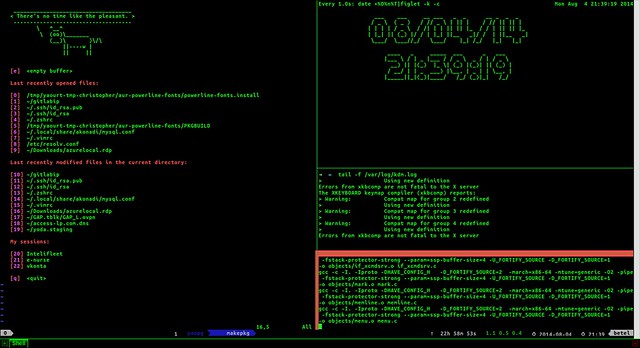
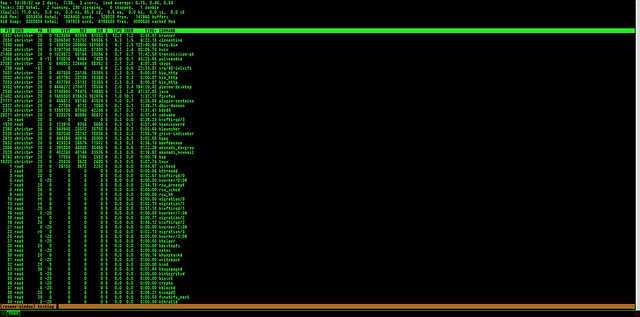
![Thanks to arm (anonymizing relay monitor) we can monitor our Tor relay operation from our beloved terminal. The relay shown is hosted on Raspberry Pi with Raspbian.]()
Tor relays can be configured to allow a predefined amount of traffic per time period and then hibernate until the next time period comes. Bandwidth isn’t always free in all VPS providers and/or ISPs, so you may want to define the AccountingMax and AccountingStart directives in your relay’s torrc file.
Now, in this post we setup a relay which is indeed a member of the global Tor network but it is not an exit node. In other words, no website or service on the Internet will see traffic coming from the public IP of our relay. This arrangement keeps us away from trouble. (Think about it: We can never know the true intentions of Tor clients, nor can we be responsible for their actions.) Having said that, we can’t stress enough that there’s always a high demand for Tor exit nodes. So if you want your contribution to the Tor network to have the highest positive impact possible, you might want to configure your relay to act as an exit relay. To do that, open /etc/tor/torrc, comment out the old ExitPolicy line and add this one:
The above directive allows all kinds of exits, i.e., traffic destined to any TCP port, but you may selectively disallow exits to certain ports (services). See the following example:
ExitPolicy reject *:25, reject *:80, accept *:*
|
This means that all exits are allowed but not those to web or SMTP servers. In general, exit policies are considered first to last and the first match wins. You may split your policy in several lines, all beginning with ExitPolicy. See, for example, the default policy of any tor relay:
ExitPolicy reject *:25
ExitPolicy reject *:119
ExitPolicy reject *:135-139
ExitPolicy reject *:445
ExitPolicy reject *:563
ExitPolicy reject *:1214
ExitPolicy reject *:4661-4666
ExitPolicy reject *:6346-6429
ExitPolicy reject *:6699
ExitPolicy reject *:6881-6999
ExitPolicy accept *:*
|
We recommend that you read the man page of torrc for more details on exit policies.
Judging from my personal experience, if you completely allow all exits on your relay then it’s almost certain that sooner rather than later you’ll get an email from your VPS provider or your ISP. This has happened to me more than four times already. In one of those cases there were complaints about downloading of infringing content (movies and TV shows) via BitTorrent. At another time, an email from my ISP was mentioning excessive malware activity originating from my public IP at home. Each time I was the recipient of such emails, I immediately modified the exit policy of the corresponding Tor instance and continued using it as a non-exit relay. After the change of the policy, I had no further (justified) complaints from the ISP/VPS provider.
My understanding is that even if your relay allows exits, it’s still highly improbable that you’ll get yourself in any sort of legal trouble. It is *not impossible* though, and occasionally it all depends on the law in your country and/or other legal precedents. So my recommendation is to always disallow exits or use the default exit policy. If your relay is hosted in a university, then you should probably get away by allowing all kinds of exits. In any case, always be cooperative and immediately comply to any requests from your ISP or VPS provider.
Congratulations on your new Tor relay — and have fun!


 The IP address against which the services are mapped needs to be reachable at all time. Normally Heartbeat would assign the designated IP address to a virtual network interface card (NIC) on the primary server for you. If the primary server goes down, the cluster will automatically shift the IP address to a virtual NIC on another of its available servers. When the primary server comes back online, it shifts the IP address back to the primary server again. This IP address is called "floating" because of its migratory properties.
The IP address against which the services are mapped needs to be reachable at all time. Normally Heartbeat would assign the designated IP address to a virtual network interface card (NIC) on the primary server for you. If the primary server goes down, the cluster will automatically shift the IP address to a virtual NIC on another of its available servers. When the primary server comes back online, it shifts the IP address back to the primary server again. This IP address is called "floating" because of its migratory properties.




 For me, the interface is basic, no-nonsense and intuitive. I like that installation is a single PHP file, and I also like that it supports alternate database systems like Postgres. If you are someone who prefers to use a Web interface over the command line, don't be ashamed. Heck, I recently managed an entire database department at a university, and I still prefer a Web-based interface. Anyway, if you're like me, you'll love Adminer. Get your copy today at
For me, the interface is basic, no-nonsense and intuitive. I like that installation is a single PHP file, and I also like that it supports alternate database systems like Postgres. If you are someone who prefers to use a Web interface over the command line, don't be ashamed. Heck, I recently managed an entire database department at a university, and I still prefer a Web-based interface. Anyway, if you're like me, you'll love Adminer. Get your copy today at