http://www.howopensource.com/2014/10/creare-secure-communication-putty
Imagine you are connected to public wireless network and want to check some admin panel that does not support HTTPS. Then you are in trouble and you need some simple trick to do the job. In this case you can create SSH tunnel to remote host and traffic to this host will be encrypted and there is nothing to worry about. Your real connection goes over SSH tunnel and its purpose is to allow traffic to pass securely through that tunnel to a remote host.
SSH tunneling is very handy in following situations:
– Accessing sensitive web resources via encrypted channel;
– Bypassing ISP/Corporate network restrictions. For example you can bypass some ports or hosts.
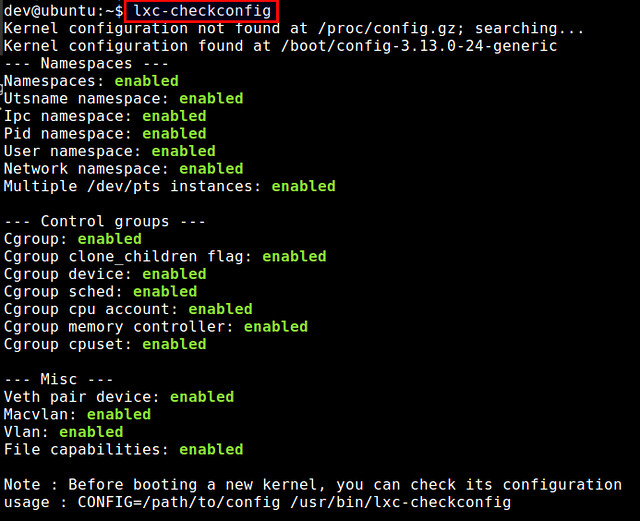
To connection from Windows to your Linux host you need PuTTY. Most probably you are already familiar with PuTTY. It is a open source SSH client, terminal emulator and network file transfer application. It supports major network protocols, such as SCP, SSH, Telnet and rlogin. PuTTY was originally written only for Windows, but now it has ports to various other OSes. You can download it from here.
Here are the steps to perform to achieve task:
1. Open PuTTY.
2. Navigate to Connection -> SSH -> Tunnels.
3. In field Source port enter port to which to connect your program (in my test scenario it will be a browser).
4. In field Destination enter destination host and port where you want to connect.
5. Click Add button.
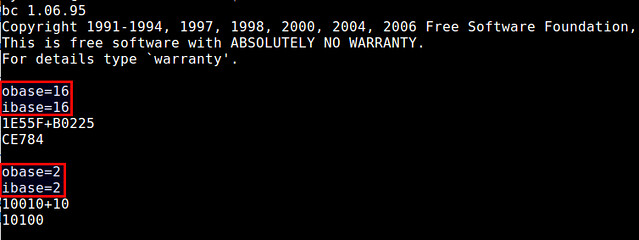
It should look something like that.
![secure communication with putty]()
![putty ssh tunneling]()
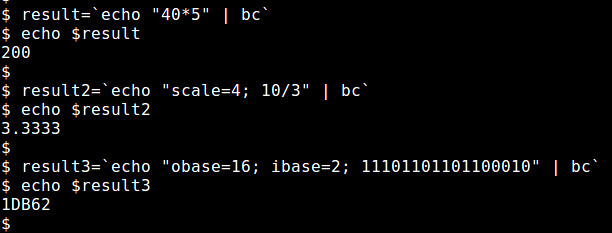
Then you need to return to main PuTTY window and to enter host to which you want to connect and actually to connect to it.
![ssh secure tunneling]()
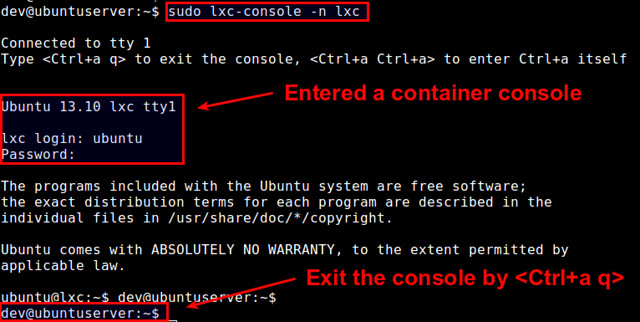
Next step is to login to that Linux host with your user name and password.
![ssh secure communication tunnel]()
When you login you just open your browser and point to localhost:8080 and then you will see output from where it points – in our scenario to remote host Apache web server.
![putty tunneling]()
Basically what happens is that we connect to localhost and port which we specify in field “Source port”. Then connection goes from our computer to remote host which we connected and all traffic is encrypted (so nothing to worry about). Then SSH daemon redirects traffic to destination which we specify in corresponding field. This could be very useful to do VNC connections over SSH which I will write very soon.
Imagine you are connected to public wireless network and want to check some admin panel that does not support HTTPS. Then you are in trouble and you need some simple trick to do the job. In this case you can create SSH tunnel to remote host and traffic to this host will be encrypted and there is nothing to worry about. Your real connection goes over SSH tunnel and its purpose is to allow traffic to pass securely through that tunnel to a remote host.
SSH tunneling is very handy in following situations:
– Accessing sensitive web resources via encrypted channel;
– Bypassing ISP/Corporate network restrictions. For example you can bypass some ports or hosts.
Advertisements
But first you need to check one setting in your SSH server configuration and if it is missing you have to add it. We are talking about PermitTunnel yes in file SSH daemon configuration file /etc/ssh/sshd_config.
cd /etc/sshIf grep command returns nothing or “PermitTunnel no” then you need to edit SSH daemon configuration file.
grep PermitTunnel sshd_config
sudo vi sshd_configWhen you open sshd_config file at the end add the following option.
Advertisements
PermitTunnel yesThen you need to restart SSH service.
sudo service ssh restartIf this option is present in your configuration file there is nothing to do. Just ignore above section.
To connection from Windows to your Linux host you need PuTTY. Most probably you are already familiar with PuTTY. It is a open source SSH client, terminal emulator and network file transfer application. It supports major network protocols, such as SCP, SSH, Telnet and rlogin. PuTTY was originally written only for Windows, but now it has ports to various other OSes. You can download it from here.
Here are the steps to perform to achieve task:
1. Open PuTTY.
2. Navigate to Connection -> SSH -> Tunnels.
3. In field Source port enter port to which to connect your program (in my test scenario it will be a browser).
4. In field Destination enter destination host and port where you want to connect.
5. Click Add button.
It should look something like that.


Then you need to return to main PuTTY window and to enter host to which you want to connect and actually to connect to it.

Next step is to login to that Linux host with your user name and password.

When you login you just open your browser and point to localhost:8080 and then you will see output from where it points – in our scenario to remote host Apache web server.

Basically what happens is that we connect to localhost and port which we specify in field “Source port”. Then connection goes from our computer to remote host which we connected and all traffic is encrypted (so nothing to worry about). Then SSH daemon redirects traffic to destination which we specify in corresponding field. This could be very useful to do VNC connections over SSH which I will write very soon.