http://www.linuxjournal.com/content/its-easier-ask-forgiveness?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+linuxjournalcom+%28Linux+Journal+-+The+Original+Magazine+of+the+Linux+Community%29&hootPostID=a8f8dba3e92f9640c81db86b05610060
...than to understand Linux permissions! Honestly though, that's not really true. Linux permissions are simple and elegant, and once you understand them, they're easy to work with. Octal notation gets a little funky, but even that makes sense once you understand why it exists.
...than to understand Linux permissions! Honestly though, that's not really true. Linux permissions are simple and elegant, and once you understand them, they're easy to work with. Octal notation gets a little funky, but even that makes sense once you understand why it exists.
Users and Groups:
First I need to address that Linux does have ACL support for file and folder permissions. It's not how things work by default, however, and ACLs were added to address the fine controls needed for some situations. Most Linux systems rely on standard POSIX permissions. That's what I'm covering here.
Every file has an owner and a group membership. If you type
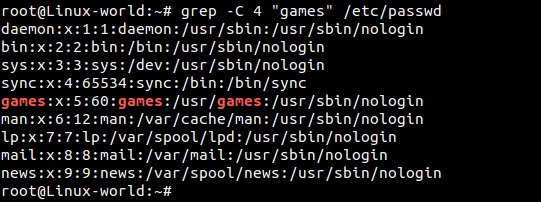
Figure 1 shows an example of what a file listing looks like. I've separated the different sections showing which fields are which. Note the first field is usually either a "d" or a "-"; the former appears on directories, and the latter appears on regular files. For files, the permissions make straightforward sense. If the "read" bit is turned on, it means that user (user, group or other) can read the contents of the file. If the "write" bit is set, it can be written to, and if the "execute" bit is set, the file can be executed. Execute bits are usually set on binary files or on scripts you want to run directly.
![]() Figure 1. Example File Listing
Figure 1. Example File Listing
On folders, the permissions work almost the same: read means the ability to see what files are in the folder, and write is the ability to save a file into the folder. Execute is a little less obvious. When the "execute" bit is set, it means the user or group can change into the directory. So the
Changing Permissions:
Although Linux systems usually come with fairly sane standards for what permissions files are created with, it's often necessary to change them. For that, you use the
Octal Notation:
In Figure 2, you can see I've shown the numeric value of each permission bit. By simply adding the numbers, it's possible to create any possibility of permissions with three numbers. Figure 3 shows a few examples of how those can be figured out.
![]() Figure 2. Numeric Value of Each Permission Bit
Figure 2. Numeric Value of Each Permission Bit
![]() Figure 3. Creating Permissions
Figure 3. Creating Permissions
So with octal notation, the following two chmod statements are functionally the same:
I urge you to play with
Linux permissions are simple, elegant and allow for some very flexible file-sharing options on a filesystem. We use them most often when installing Web applications, because the Web server runs as a particular user, and that user (or group) needs to have access to the files it's attempting to serve.
First I need to address that Linux does have ACL support for file and folder permissions. It's not how things work by default, however, and ACLs were added to address the fine controls needed for some situations. Most Linux systems rely on standard POSIX permissions. That's what I'm covering here.
Every file has an owner and a group membership. If you type
ls -l, you'll see the owner and group on all the files and folders in your current directory. POSIX permissions allow you to control read, write and execute abilities for the user, group and a third set of users, "other". Using those three aspects on three different sets of users allows for some fairly complex "who can do what" on a filesystem. Figure 1 shows an example of what a file listing looks like. I've separated the different sections showing which fields are which. Note the first field is usually either a "d" or a "-"; the former appears on directories, and the latter appears on regular files. For files, the permissions make straightforward sense. If the "read" bit is turned on, it means that user (user, group or other) can read the contents of the file. If the "write" bit is set, it can be written to, and if the "execute" bit is set, the file can be executed. Execute bits are usually set on binary files or on scripts you want to run directly.
 Figure 1. Example File Listing
Figure 1. Example File Listing On folders, the permissions work almost the same: read means the ability to see what files are in the folder, and write is the ability to save a file into the folder. Execute is a little less obvious. When the "execute" bit is set, it means the user or group can change into the directory. So the
cd command will work as long as you have execute access to a folder. Changing Permissions:
Although Linux systems usually come with fairly sane standards for what permissions files are created with, it's often necessary to change them. For that, you use the
chmod tool. The format is to use:
chmod u+rw,g-r,o+rwx file.txt
chmod ugo+rw file.txt
chmod ugo-rw file.txt
chmod -rw file.txt
chmod u-rw,g-rw,o-rw file.txt
Octal Notation:
In Figure 2, you can see I've shown the numeric value of each permission bit. By simply adding the numbers, it's possible to create any possibility of permissions with three numbers. Figure 3 shows a few examples of how those can be figured out.
 Figure 2. Numeric Value of Each Permission Bit
Figure 2. Numeric Value of Each Permission Bit  Figure 3. Creating Permissions
Figure 3. Creating Permissions So with octal notation, the following two chmod statements are functionally the same:
chmod ug+rw,ug-x,o+r,o-wx file.txt
chmod 662 file.txt
I urge you to play with
chmod a bit until you get the results you expect when using octal notation. Then, just for fun, see if you can string together a bunch of pluses and minuses to get the same results! Linux permissions are simple, elegant and allow for some very flexible file-sharing options on a filesystem. We use them most often when installing Web applications, because the Web server runs as a particular user, and that user (or group) needs to have access to the files it's attempting to serve.




.png)


























 Figure 1. Octal Notation
Figure 1. Octal Notation