http://www.cyberciti.biz/faq/debian-ubuntu-linux-delete-old-kernel-images-command
I'm a new Ubuntu Linux user and noticed that old kernel still exists in my system. Why doesn't Ubuntu remove old kernels automatically? How do I delete old unused kernel images to free disk space. How to remove unused old kernel images on Ubuntu Linux safely?
You need to delete and/or remove old kernels from system manually. Ubuntu and Debian based system keeps old kernel images so that system can be booted if newer kernel failed. The safest way to purge and remove old kernel is as follows. In this tutorial you will learn how to delete unused old kernel images on Ubuntu or Debian Linux to free disk space as well as the various state of linux-image package.
Sample outputs:
Sample outputs:
![Fig.01: Check what kernel image(s) are installed on your system]()
OR
Sample outputs:
Sample outputs:
Sample outputs:
I'm a new Ubuntu Linux user and noticed that old kernel still exists in my system. Why doesn't Ubuntu remove old kernels automatically? How do I delete old unused kernel images to free disk space. How to remove unused old kernel images on Ubuntu Linux safely?
You need to delete and/or remove old kernels from system manually. Ubuntu and Debian based system keeps old kernel images so that system can be booted if newer kernel failed. The safest way to purge and remove old kernel is as follows. In this tutorial you will learn how to delete unused old kernel images on Ubuntu or Debian Linux to free disk space as well as the various state of linux-image package.
Step #1: Boot into new kernel
First, boot into newly installed kernel. Verify this with the following command:$ uname -mrs
$ uname -aSample outputs:
Linux server1 3.13.0-68-generic #111-Ubuntu SMP Fri Nov 6 18:17:06 UTC 2015 x86_64 x86_64 x86_64 GNU/LinuxTo list all installed Linux kernel images, enter:
# dpkg --list | egrep -i --color 'linux-image|linux-headers'Sample outputs:
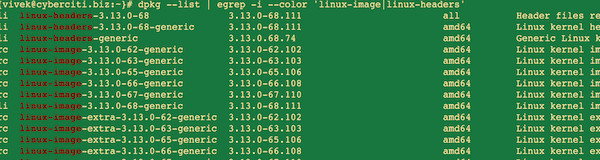
Fig.01: Check what kernel image(s) are installed on your system (click to enlarge)
Step #2: Delete unwanted and unused kernel images
You can remove kernel images one by one using the following syntax:# apt-get --purge remove linux-image-3.13.0-67-genericOR
$ sudo apt-get --purge remove linux-image-3.13.0-67-genericA note about newer Ubuntu and Debian system
On newer system all obsolete kernels and headers should automatically be flagged as no more needed, and thus can be purged with the following single command:$ sudo apt-get autoremoveUnderstanding package states in Ubuntu and Debian Linux
Consider the following example:# dpkg --list | grep linux-imageSample outputs:
rc linux-image-3.13.0-62-generic 3.13.0-62.102 amd64 Linux kernel image for version 3.13.0 on 64 bit x86 SMPThe first column indicates package flags like rc, ii. So, what do the various dpkg flags like 'ii''rc' mean?
rc linux-image-3.13.0-63-generic 3.13.0-63.103 amd64 Linux kernel image for version 3.13.0 on 64 bit x86 SMP
rc linux-image-3.13.0-65-generic 3.13.0-65.106 amd64 Linux kernel image for version 3.13.0 on 64 bit x86 SMP
rc linux-image-3.13.0-66-generic 3.13.0-66.108 amd64 Linux kernel image for version 3.13.0 on 64 bit x86 SMP
rc linux-image-3.13.0-67-generic 3.13.0-67.110 amd64 Linux kernel image for version 3.13.0 on 64 bit x86 SMP
ii linux-image-3.13.0-68-generic 3.13.0-68.111 amd64 Linux kernel image for version 3.13.0 on 64 bit x86 SMP
rc linux-image-extra-3.13.0-62-generic 3.13.0-62.102 amd64 Linux kernel extra modules for version 3.13.0 on 64 bit x86 SMP
rc linux-image-extra-3.13.0-63-generic 3.13.0-63.103 amd64 Linux kernel extra modules for version 3.13.0 on 64 bit x86 SMP
rc linux-image-extra-3.13.0-65-generic 3.13.0-65.106 amd64 Linux kernel extra modules for version 3.13.0 on 64 bit x86 SMP
rc linux-image-extra-3.13.0-66-generic 3.13.0-66.108 amd64 Linux kernel extra modules for version 3.13.0 on 64 bit x86 SMP
rc linux-image-extra-3.13.0-67-generic 3.13.0-67.110 amd64 Linux kernel extra modules for version 3.13.0 on 64 bit x86 SMP
ii linux-image-extra-3.13.0-68-generic 3.13.0-68.111 amd64 Linux kernel extra modules for version 3.13.0 on 64 bit x86 SMP
ii linux-image-generic 3.13.0.68.74 amd64 Generic Linux kernel image
- rc: It means package is in remove/deinstall state and only config file exists.
- ii: It means package is in install state and it is 100% installed on the system.
# x=$(dpkg --list | grep -i linux-image | grep ^rc| awk '{ print $2}')
# echo "$x"
# apt-get --purge remove $xSample outputs:
Reading package lists... DoneType the following command again to see the results:
Building dependency tree
Reading state information... Done
The following packages will be REMOVED:
linux-image-3.13.0-62-generic* linux-image-3.13.0-63-generic*
linux-image-3.13.0-65-generic* linux-image-3.13.0-66-generic*
linux-image-3.13.0-67-generic* linux-image-extra-3.13.0-62-generic*
linux-image-extra-3.13.0-63-generic* linux-image-extra-3.13.0-65-generic*
linux-image-extra-3.13.0-66-generic* linux-image-extra-3.13.0-67-generic*
0 upgraded, 0 newly installed, 10 to remove and 0 not upgraded.
After this operation, 0 B of additional disk space will be used.
Do you want to continue? [Y/n] y
(Reading database ... 65623 files and directories currently installed.)
Removing linux-image-3.13.0-62-generic (3.13.0-62.102) ...
Purging configuration files for linux-image-3.13.0-62-generic (3.13.0-62.102) ...
Examining /etc/kernel/postrm.d .
run-parts: executing /etc/kernel/postrm.d/initramfs-tools 3.13.0-62-generic /boot/vmlinuz-3.13.0-62-generic
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 3.13.0-62-generic /boot/vmlinuz-3.13.0-62-generic
Removing linux-image-3.13.0-63-generic (3.13.0-63.103) ...
Purging configuration files for linux-image-3.13.0-63-generic (3.13.0-63.103) ...
Examining /etc/kernel/postrm.d .
run-parts: executing /etc/kernel/postrm.d/initramfs-tools 3.13.0-63-generic /boot/vmlinuz-3.13.0-63-generic
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 3.13.0-63-generic /boot/vmlinuz-3.13.0-63-generic
Removing linux-image-3.13.0-65-generic (3.13.0-65.106) ...
Purging configuration files for linux-image-3.13.0-65-generic (3.13.0-65.106) ...
Examining /etc/kernel/postrm.d .
run-parts: executing /etc/kernel/postrm.d/initramfs-tools 3.13.0-65-generic /boot/vmlinuz-3.13.0-65-generic
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 3.13.0-65-generic /boot/vmlinuz-3.13.0-65-generic
Removing linux-image-3.13.0-66-generic (3.13.0-66.108) ...
Purging configuration files for linux-image-3.13.0-66-generic (3.13.0-66.108) ...
Examining /etc/kernel/postrm.d .
run-parts: executing /etc/kernel/postrm.d/initramfs-tools 3.13.0-66-generic /boot/vmlinuz-3.13.0-66-generic
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 3.13.0-66-generic /boot/vmlinuz-3.13.0-66-generic
Removing linux-image-3.13.0-67-generic (3.13.0-67.110) ...
Purging configuration files for linux-image-3.13.0-67-generic (3.13.0-67.110) ...
Examining /etc/kernel/postrm.d .
run-parts: executing /etc/kernel/postrm.d/initramfs-tools 3.13.0-67-generic /boot/vmlinuz-3.13.0-67-generic
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 3.13.0-67-generic /boot/vmlinuz-3.13.0-67-generic
Removing linux-image-extra-3.13.0-62-generic (3.13.0-62.102) ...
Purging configuration files for linux-image-extra-3.13.0-62-generic (3.13.0-62.102) ...
Removing linux-image-extra-3.13.0-63-generic (3.13.0-63.103) ...
Purging configuration files for linux-image-extra-3.13.0-63-generic (3.13.0-63.103) ...
Removing linux-image-extra-3.13.0-65-generic (3.13.0-65.106) ...
Purging configuration files for linux-image-extra-3.13.0-65-generic (3.13.0-65.106) ...
Removing linux-image-extra-3.13.0-66-generic (3.13.0-66.108) ...
Purging configuration files for linux-image-extra-3.13.0-66-generic (3.13.0-66.108) ...
Removing linux-image-extra-3.13.0-67-generic (3.13.0-67.110) ...
Purging configuration files for linux-image-extra-3.13.0-67-generic (3.13.0-67.110) ...
# dpkg --list | egrep -i --color 'linux-image|linux-headers'Sample outputs:
ii linux-headers-3.13.0-68 3.13.0-68.111 all Header files related to Linux kernel version 3.13.0
ii linux-headers-3.13.0-68-generic 3.13.0-68.111 amd64 Linux kernel headers for version 3.13.0 on 64 bit x86 SMP
ii linux-headers-generic 3.13.0.68.74 amd64 Generic Linux kernel headers
ii linux-image-3.13.0-68-generic 3.13.0-68.111 amd64 Linux kernel image for version 3.13.0 on 64 bit x86 SMP
ii linux-image-extra-3.13.0-68-generic 3.13.0-68.111 amd64 Linux kernel extra modules for version 3.13.0 on 64 bit x86 SMP
ii linux-image-generic 3.13.0.68.74 amd64 Generic Linux kernel image

 So you have a killer app idea and you’re ready to turn it into a reality and take it to market. No doubt you’re itching to start getting your first downloads, reviews and profits… But there’s just one problem: you don’t have a clue where to start!
So you have a killer app idea and you’re ready to turn it into a reality and take it to market. No doubt you’re itching to start getting your first downloads, reviews and profits… But there’s just one problem: you don’t have a clue where to start!









 Follow the steps to launch the emulator running your app. Be patient, it can sometimes take an age to load up… If it never loads up, you can consider ‘packaging’ the app in order to create an APK. Drag this onto your Android device and double click on it to install and run it.
Follow the steps to launch the emulator running your app. Be patient, it can sometimes take an age to load up… If it never loads up, you can consider ‘packaging’ the app in order to create an APK. Drag this onto your Android device and double click on it to install and run it.








 WARNING! The seq command print a sequence of numbers and it is here due to historical reasons. The following examples is only recommend for older bash version. All users (bash v3.x+) are recommended to use the above syntax.
WARNING! The seq command print a sequence of numbers and it is here due to historical reasons. The following examples is only recommend for older bash version. All users (bash v3.x+) are recommended to use the above syntax.