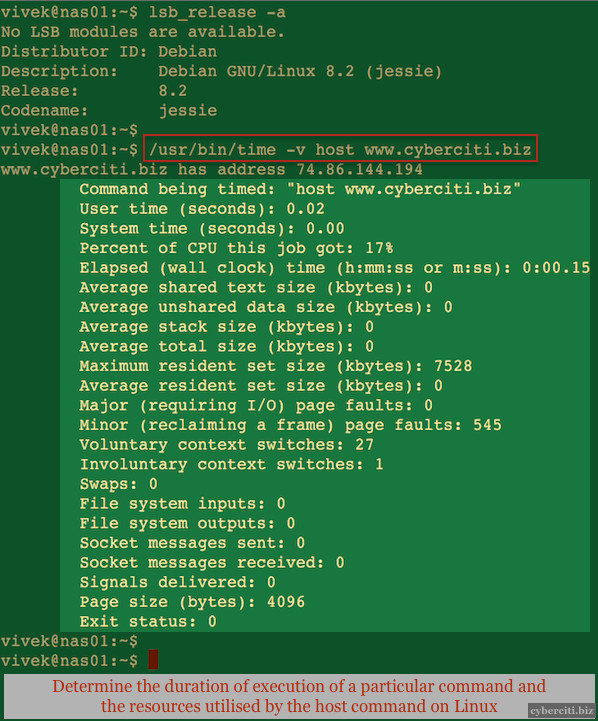
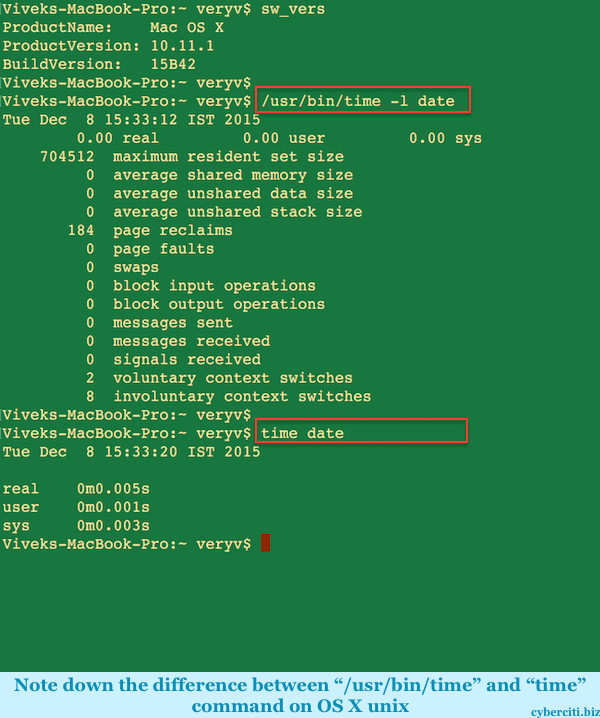
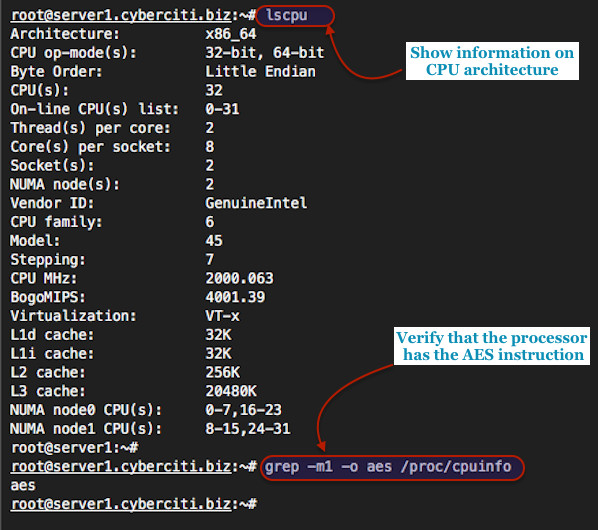
http://www.linuxjournal.com/content/take-control-your-pc-uefi-secure-boot
UEFI (Unified Extensible Firmware Interface) is the open, multi-vendor replacement for the aging BIOS standard, which first appeared in IBM computers in 1976. The UEFI standard is extensive, covering the full boot architecture. This article focuses on a single useful but typically overlooked feature of UEFI: secure boot.
Often maligned, you've probably encountered UEFI secure boot only when you disabled it during initial setup of your computer. Indeed, the introduction of secure boot was mired with controversy over Microsoft being in charge of signing third-party operating system code that would boot under a secure boot environment.
In this article, we explore the basics of secure boot and how to take control of it. We describe how to install your own keys and sign your own binaries with those keys. We also show how you can build a single standalone GRUB EFI binary, which will protect your system from tampering, such as cold-boot attacks. Finally, we show how full disk encryption can be used to protect the entire hard disk, including the kernel image (which ordinarily needs to be stored unencrypted).
UEFI Secure Boot
Secure boot is designed to protect a system against malicious code being loaded and executed early in the boot process, before the operating system has been loaded. This is to prevent malicious software from installing a "bootkit" and maintaining control over a computer to mask its presence. If an invalid binary is loaded while secure boot is enabled, the user is alerted, and the system will refuse to boot the tampered binary.
On each boot-up, the UEFI firmware inspects each EFI binary that is loaded and ensures that it has either a valid signature (backed by a locally trusted certificate) or that the binary's checksum is present on an allowed list. It also verifies that the signature or checksum does not appear in the deny list. Lists of trusted certificates or checksums are stored as EFI variables within the non-volatile memory used by the UEFI firmware environment to store settings and configuration data.
UEFI Key Overview
The four main EFI variables used for secure boot are shown in Figure a. The Platform Key (often abbreviated to PK) offers full control of the secure boot key hierarchy. The holder of the PK can install a new PK and update the KEK (Key Exchange Key). This is a second key, which either can sign executable EFI binaries directly or be used to sign the db and dbx databases. The db (signature database) variable contains a list of allowed signing certificates or the cryptographic hashes of allowed binaries. The dbx is the inverse of db, and it is used as a blacklist of specific certificates or hashes, which otherwise would have been accepted, but which should not be able to run. Only the KEK and db (shown in green) keys can sign binaries that may boot the system.
![]()
Figure a. Secure Boot Keys
The PK on most systems is issued by the manufacturer of the hardware, while a KEK is held by the operating system vendor (such as Microsoft). Hardware vendors also commonly have their own KEK installed (since multiple KEKs can be present). To take full ownership of a computer using secure boot, you need to replace (at a minimum) the PK and KEK, in order to prevent new keys being installed without your consent. You also should replace the signature database (db) if you want to prevent commercially signed EFI binaries from running on your system.
Secure boot is designed to allow someone with physical control over a computer to take control of the installed keys. A pre-installed manufacturer PK can be programmatically replaced only by signing it with the existing PK. With physical access to the computer, and access to the UEFI firmware environment, this key can be removed and a new one installed. Requiring physical access to the system to override the default keys is an important security requirement of secure boot to prevent malicious software from completing this process. Note that some locked-down ARM-based devices implement UEFI secure boot without the ability to change the pre-installed keys.
Testing Procedure
You can follow these procedures on a physical computer, or alternatively in a virtualized instance of the Intel Tianocore reference UEFI implementation. The
ovmf package available in most Linux distributions includes this. The QEMU virtualization tool can launch an instance of
ovmf for experimentation. Note that the
fatargument specifies that a directory,
storage, will be presented to the virtualized firmware as a persistent storage volume. Create this directory in the current working directory, and launch QEMU:
qemu-system-x86_64 -enable-kvm -net none \
-m 1024 -pflash /usr/share/ovmf/ovmf_x64.bin \
-hda fat:storage/
Files present in this folder when starting QEMU will appear as a volume to the virtualized UEFI firmware. Note that files added to it after starting QEMU will not appear in the system—restart QEMU and they will appear. This directory can be used to hold the public keys you want to install to the UEFI firmware, as well as UEFI images to be booted later in the process.
Generating Your Own Keys
Secure boot keys are self-signed 2048-bit RSA keys, in X.509 certificate format. Note that most implementations do not support key lengths greater than 2048 bits at present. You can generate a 2048-bit keypair (with a validity period of 3650 days, or ten years) with the following
openssl command:
openssl req -new -x509 -newkey rsa:2048 -keyout PK.key \
-out PK.crt -days 3650 -subj "/CN=My Secure PK/"
The CN subject can be customized as you wish, and its value is not important. The resulting PK.key is a private key, and PK.crt is the corresponding certificate (containing the public key), which you will install into the UEFI firmware shortly. You should store the private key securely on an encrypted storage device in a safe place.
Now you can carry out the same process for both the KEK and for the db key. Note that the db and KEK EFI variables can contain multiple keys (and in the case of db, SHA256 hashes of bootable binaries), although for simplicity, this article considers only storing a single certificate in each. This is more than adequate for taking control of your own computer. Once again, the .key files are private keys, which should be stored securely, and the .crt files are public certificates to be installed into your UEFI system variables.
Taking Ownership and Installing Keys
Every UEFI firmware interface differs, and it is therefore not possible to provide step-by-step instructions on how to install your own keys. Refer to your motherboard or laptop's instruction manual, or search on-line for the maker of the UEFI firmware. Enter the UEFI firmware interface, usually by holding a key down at boot time, and locate the security menu. Here there should be a section or submenu for secure boot. Change the mode control to "custom" mode. This should allow you to access the key management menus.
![]()
Figure 1. Enabling Secure Boot and Entering Custom Mode
At this point, you should make a backup of the UEFI platform keys currently installed. You should not need this, since there should be an option within your UEFI firmware interface to restore the default keys, but it does no harm to be cautious. There should be an option to export or save the current keys to a USB Flash drive. It is best to format this with the FAT filesystem if you have any issues with it being detected.
After you have copied the backup keys somewhere safe, load the public certificate (.crt) files you created previously onto the USB Flash drive. Take care not to mix them up with the backup certificates from earlier. Enter the UEFI firmware interface, and use the option to reset or clear all existing secure boot keys.
![]()
Figure 2. Erasing the Existing Platform Key
This also might be referred to as "taking ownership" of secure boot. Your system is now in secure boot "setup" mode, which will remain until a new PK is installed. At this point, the EFI PK variable is unprotected by the system, and a new value can be loaded in from the UEFI firmware interface or from software running on the computer (such as an operating system).
![]()
Figure 3. Loading a New Key from a Storage Device
At this point, you should disable secure boot temporarily, in order to continue following this article. Your newly installed keys will remain in place for when secure boot is enabled.
Signing Binaries
After you have installed your custom UEFI signing keys, you need to sign your own EFI binaries. There are a variety of different ways to build (or obtain) these. Most modern Linux bootloaders are EFI-compatible (for example, GRUB 2, rEFInd or gummiboot), and the Linux kernel itself can be built as a bootable EFI binary since version 3.3. It's possible to sign and boot any valid EFI binary, although the approach you take here depends on your preference.
One option is to sign the kernel image directly. If your distribution uses a binary kernel, you would need to sign each new kernel update before rebooting your system. If you use a self-compiled kernel, you would need to sign each kernel after building it. This approach, however, requires you to keep on top of kernel updates and sign each image. This can become arduous, especially if you use a rolling-release distribution or test mainline release candidates. An alternative, and the approach we used in this article, is to sign a locked-down UEFI-compatible bootloader (GRUB 2 in the case of this article), and use this to boot various kernels from your system.
Some distributions configure GRUB to validate kernel image signatures against a distribution-specified public key (with which they sign all kernel binaries) and disable editing of the kernel
cmdline variable when secure boot is in use. You therefore should refer to the documentation for your distribution, as the section on ensuring your boot images are encrypted would not be essential in this case.
The Linux
sbsigntools package is available from the repositories of most Linux distributions and is a good first port of call when signing UEFI binaries. UEFI secure boot binaries should be signed with an Authenticode-format signature. The command of interest is
sbsign, which is invoked as follows:
sbsign --key DB.key --cert DB.crt unsigned.efi \
--output signed.efi
Due to subtle variations in the implementation of the UEFI standards, some systems may reject a correctly signed binary from
sbsign. The best alternative we found was to use the
osslsigncode utility, which also generates Authenticode signatures. Although this tool was not specifically intended for use with secure boot, it produces signatures that match the required specification. Since
osslsigncode does not appear to be commonly included in distribution repositories, you should build it from its source code. The process is relatively straightforward and simply requires running
make, which will produce the executable binary. If you encounter any issues, ensure you have installed
openssland
curl, which are dependencies of the package. (See Resources for a link to the source code repository.)
Binaries are signed with
osslsigntool in a similar manner to
sbsign (note that the hash is defined as sha256 per the UEFI specification; this should not be altered):
osslsigncode -certs DB.crt -key DB.key \
-h sha256 -in unsigned.efi -out signed.efi
Booting with UEFI
After you have signed an EFI binary (such as the GRUB bootloader binary), the obvious next step is to test it. Computers using the legacy BIOS boot technology load the initial operating system bootloader from the MBR (master boot record) of the selected boot device. The MBR contains code to load a further (and larger) bootloader held within the disk, which loads the operating system. In contrast, UEFI is designed to allow for more than one bootloader to exist on one drive, without the need for those bootloaders to cooperate or even know the others exist.
Bootable UEFI binaries are located on a storage device (such as a hard disk) within a standard path. The partition containing these binaries is referred to as the EFI System Partition. It has a partition ID of 0xEF00 in gdisk, the GPT-compatible equivalent to fdisk. This partition is conventionally located at the beginning of the filesystem and formatted with a FAT32 filesystem. UEFI-bootable binaries are then stored as files in the EFI/BOOT/ directory.
This signed binary should now boot if it is placed at EFI/BOOT/BOOTX64.EFI within the EFI system partition or an external drive, which is set as the boot device. It is possible to have multiple EFI binaries available on one EFI system partition, which makes it easier to create a multi-boot setup. For that to work however, the UEFI firmware needs a boot entry created in its non-volatile memory. Otherwise, the default filename (BOOTX64.EFI) will be used, if it exists.
To add a new EFI binary to your firmware's list of available binaries, you should use the
efibootmgr utility. This tool can be found in distribution repositories and often is used automatically by the installers for popular bootloaders, such as GRUB.
At this point, you should re-enable secure boot within your UEFI firmware. To ensure that secure boot is operating correctly, you should attempt to boot an unsigned EFI binary. To do so, you can place a binary (such as an unsigned GRUB EFI binary) at EFI/BOOT/BOOTX64.EFI on a FAT32-formatted USB Flash drive. Use the UEFI firmware interface to set this drive as the current boot drive, and ensure that a security warning appears, which halts the boot process. You also should verify that an image signed with the default UEFI secure boot keys does not boot—an Ubuntu 12.04 (or newer) CD or bootable USB stick should allow you to verify this. Finally, you should ensure that your self-signed binary boots correctly and without error.
Installing Standalone GRUB
By default, the GRUB bootloader uses a configuration file stored at /boot/grub/grub.cfg. Ordinarily, this file could be edited by anyone able to modify the contents of your /boot partition, either by booting to another OS or by placing your drive in another computer.
Bootloader Security
Prior to the advent of secure boot and UEFI, someone with physical access to a computer was presumed to have full access to it. User passwords could be bypassed by simply adding
init=/bin/bash to the kernel
cmdline parameter, and the computer would boot straight up into a root shell, with full access to all files on the system.
Setting up full disk encryption is one way to protect your data from physical attack—if the contents of the hard disk is encrypted, the disk must be decrypted before the system can boot. It is not possible to mount the disk's partitions without the decryption key, so the data is protected.
Another approach is to prevent an attacker from altering the kernel cmdline parameter. This approach is easily bypassed on most computers, however, by installing a new bootloader. This bootloader need not respect the restrictions imposed by the original bootloader. In many cases, replacing the bootloader may prove unnecessary—GRUB and other bootloaders are fully configurable by means of a separate configuration file, which could be edited to bypass security restrictions, such as passwords.
Therefore, there would be no real security advantage in signing the GRUB bootloader, since the signed (and verified) bootloader would then load unsigned modules from the hard disk and use an unsigned configuration file. By having GRUB create a single, bootable EFI binary, containing all the necessary modules and configuration files, you no longer need to trust the modules and configuration file of your GRUB binary. After signing the GRUB binary, it cannot be modified without secure boot rejecting it and refusing to load. This failure would alert you to someone attempting to compromise your computer by modifying the bootloader.
As mentioned earlier, this step may not be necessary on some distributions, as their GRUB bootloader automatically will enforce similar restrictions and checks on kernels when booted with secure boot enabled. So, this section is intended for those who are not using such a distribution or who wish to implement something similar themselves for learning purposes.
To create a standalone GRUB binary, the
grub-mkstandalonetool is needed. This tool should be included as part of recent GRUB2 distribution packages:
grub-mkstandalone -d /usr/lib/grub/x86_64-efi/ \
-O x86_64-efi --modules="part_gpt part_msdos" \
--fonts="unicode" --locales="en@quot" \
--themes="" -o "/home/user/grub-standalone.efi" \
"boot/grub/grub.cfg=/boot/grub/grub.cfg"
A more detailed explanation of the arguments used here is available on the man page for
grub-mkstandalone. The significant arguments are
-o, which specifies the output file to be used, and the final string argument, specifying the path to the current GRUB configuration file. The resulting standalone GRUB binary is directly bootable and contains a memdisk, which holds the configuration file and modules, as well as the configuration file. This GRUB binary now can be signed and used to boot the system. Note that this process should be repeated when the GRUB configuration file is re-generated, such as after adding a new kernel, changing boot parameters or after adding a new operating system to the list, since the embedded configuration file will be out of date with the regular system one.
A Licensing Warning
As GRUB 2 is licensed under the GPLv3 (or later), this raises one consideration to be aware of. Although not a consideration for individual users (who simply can install new secure boot keys and boot a modified bootloader), if the GRUB 2 bootloader (or indeed any other GPL-v3-licensed bootloader) was signed with a private signing key, and the distributed computer system was designed to prevent the use of unsigned bootloaders, use of the GPL-v3-licensed software would not be in compliance with the licence. This is a result of the so-called anti-tivo'ization clause of GPLv3, which requires that users be able to install and execute their own modified version of GPLv3 software on a system, without being technically restricted from doing so.
Locking Down GRUB
To prevent a malicious user from modifying the kernel cmdline of your system (for example, to point to a different init binary), a GRUB password should be set. GRUB passwords are stored within the configuration file, after being hashed with a cryptographic hashing function. Generate a password hash with the
grub-mkpasswd-pbkdf2 command, which will prompt you to enter a password.
The PBKDF2 function is a slow hash, designed to be computationally intensive and prevent brute-force attacks against the password. Its performance is adjusted using the
-c parameter, if desired, to slow the process further on a fast computer by carrying out more rounds of PBKDF2. The default is for 10,000 rounds. After copying this password hash, it should be added to your GRUB configuration files (which normally are located in /etc/grub.d or similar). In the file 40_custom, add the following:
set superusers="root"
password_pbkdf2 root
This will create a GRUB superuser account named root, which is able to boot any GRUB entry, edit existing boot items and enter a GRUB console. Without further configuration, this password also will be required to boot the system. If you prefer to have yet another password on boot-up, you can skip the next step. With full disk encryption in use though, there is little need in requiring a password on each boot-up.
To remove the requirement for the superuser password to be entered on a normal boot-up, edit the standard boot menu template (normally /etc/grub.d/10-linux), and locate the line creating a regular menu entry. It should look somewhat similar to this:
echo "menuentry '$(echo "$title" | grub_quote)'
↪${CLASS} \$menuentry_id_option
↪'gnulinux-$version-$type-$boot_device_id' {" | sed
↪"s/^/$submenu_indentation/"
Change this line by adding the argument
--unrestricted, before the opening curly bracket. This change tells GRUB that booting this entry does not require a password prompt. Depending on your distribution and GRUB version, the exact contents of the line may differ. The resulting line should be similar to this:
echo "menuentry '$(echo "$title" | grub_quote)' ${CLASS}
↪\$menuentry_id_option
↪'gnulinux-$version-$type-$boot_device_id'
↪--unrestricted {" | sed "s/^/$submenu_indentation/"
After adding a superuser account and configuring the need (or otherwise) for boot-up passwords, the main GRUB configuration file should be re-generated. The command for this is distribution-specific, but is often
update-grub or
grub-mkconfig. The standalone GRUB binary also should be re-generated and tested.
Protecting the Kernel
At this point, you should have a system capable of booting a signed (and password-protected) GRUB bootloader. An adversary without access to your keys would not be able to modify the bootloader or its configuration or modules. Likewise, attackers would not be able to change the parameters passed by the bootloader to the kernel. They could, however, modify your kernel image (by swapping the hard disk into another computer). This would then be booted by GRUB. Although it is possible for GRUB to verify kernel image signatures, this requires you to re-sign each kernel update.
An alternative approach is to use full disk encryption to protect the full system, including kernel images, the root filesystem and your home directory. This prevents someone from removing your computer's drive and accessing your data or modifying it—without knowing your encryption password, the drive contents will be unreadable (and thus unmodifiable).
Most on-line guides will show full disk encryption but leave a separate, unencrypted /boot partition (which holds the kernel and initrd images) for ease of booting. By only creating a single, encrypted root partition, there won't be an unencrypted kernel or initrd stored on the disk. You can, of course, create a separate boot partition and encrypt it using
dm-crypt as normal, if you prefer.
The full process of carrying out full disk encryption including the boot partition is worthy of an article in itself, given the various distribution-specific changes necessary. A good starting point, however, is the ArchLinux Wiki (see Resources). The main difference from a conventional encryption setup is the use of the GRUB
GRUB_ENABLE_CRYPTODISK=yconfiguration parameter, which tells GRUB to attempt to decrypt an encrypted volume prior to loading the main GRUB menu.
To avoid having to enter the encryption password twice per boot-up, the system's
/etc/crypttab can be used to decrypt the filesystem with a keyfile automatically. This keyfile then can be included in the (encrypted) initrd of the filesystem (refer to your distribution's documentation to find out how to add this to the initrd, so it will be included each time it is regenerated for a kernel update).
This keyfile should be owned by the root user and does not require any user or group to have read access to it. Likewise, you should give the initrd image (in the boot partition) the same protection to prevent it from being accessed while the system is powered up and the keyfile is being extracted.
Final Considerations
UEFI secure boot allows you to take control over what code can run on your computer. Installing your own keys allows you to prevent malicious people from easily booting their own code on your computer. Combining this with full disk encryption will keep your data protected against unauthorized access and theft, and prevent an attacker from tricking you into booting a malicious kernel.
As a final step, you should apply a password to your UEFI setup interface, in order to prevent a physical attacker from gaining access to your computer's setup interface and installing their own PK, KEK and db key, as these instructions did. You should be aware, however, that a weakness in your motherboard or laptop's implementation of UEFI could potentially allow this password to be bypassed or removed, and that the ability to re-flash the UEFI firmware through a "rescue mode" on your system could potentially clear NVRAM variables. Nonetheless, by taking control of secure boot and using it to protect your system, you should be better protected against malicious software or those with temporary physical access to your computer.
Resources
Information about third-party secure boot keys:
http://mjg59.dreamwidth.org/23400.html More information about the keys and inner workings of secure boot:
http://blog.hansenpartnership.com/the-meaning-of-all-the-uefi-keys osslsigncode repository:
http://sourceforge.net/projects/osslsigncode ArchLinux Wiki instructions for fully encrypted systems:
https://wiki.archlinux.org/index.php/Dm-crypt/Encrypting_an_entire_system#Encrypted_boot_partition_.28GRUB.29 Guide for full-disk encryption including kernel image:
http://www.pavelkogan.com/2014/05/23/luks-full-disk-encryption Fedora Wiki on its secure boot implementation:
https://fedoraproject.org/wiki/Features/SecureBoot























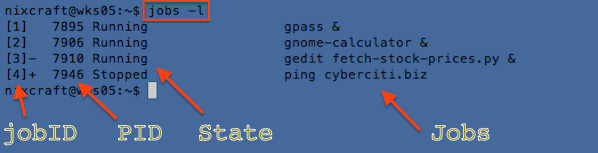
 WARNING! These examples may result into data loss if not executed properly (see "
WARNING! These examples may result into data loss if not executed properly (see "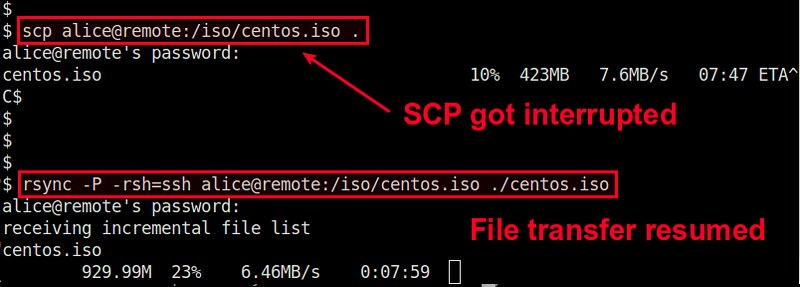
 Figure a. Secure Boot Keys
Figure a. Secure Boot Keys  Figure 1. Enabling Secure Boot and Entering Custom Mode
Figure 1. Enabling Secure Boot and Entering Custom Mode  Figure 2. Erasing the Existing Platform Key
Figure 2. Erasing the Existing Platform Key  Figure 3. Loading a New Key from a Storage Device
Figure 3. Loading a New Key from a Storage Device