http://www.linux-server-security.com/linux_servers_howtos/linux_monitor_services_monit.html
When you work with computers things don’t always go quite as expected.
Imagine that your developers have spent months developing a new groundbreaking application, frequently battling against late nights, stressed out bosses and unrealistic targets.
As the battle-hardened Sysadmin you’ve done your job beautifully. The servers that you finished configuring some time ago have had shakedowns and smoke tests and by all accounts look pretty robust. You’ve got N+1 rattling around every nook and cranny of your network and server infrastructure and you’ve been all ready for the launch for over a month.
And, days before the launch, as the antepenultimate software deployment is pushed out onto the servers by the developers, you are faced with a very unwelcome horror. In the first instance the finger instance is pointed squarely at you. Why are your servers failing? Who specified them? Who said that they would be able to cope with demand? There aren’t even any customers using the service yet and your servers can’t deal with the load, what have you misconfigured?
After two minutes of stress and self doubt you realise that thankfully neither the hardware or your system config are creaking at the seams in any way shape or form. Instead there’s a serious application fault, the logs are full of errors, due to the developers’ coding. After gently exercising some of your persuasion techniques (who said soft skills aren’t important for Syadmins?) the coders concede that it’s their problem.
Sadly this doesn’t help much however since T-10 is imminent. You can hack together a shell script to act as a watchdog and refresh the application if an error is detected but there’s not much time to get that properly tested because there’s still a few other small jobs for you to complete too.
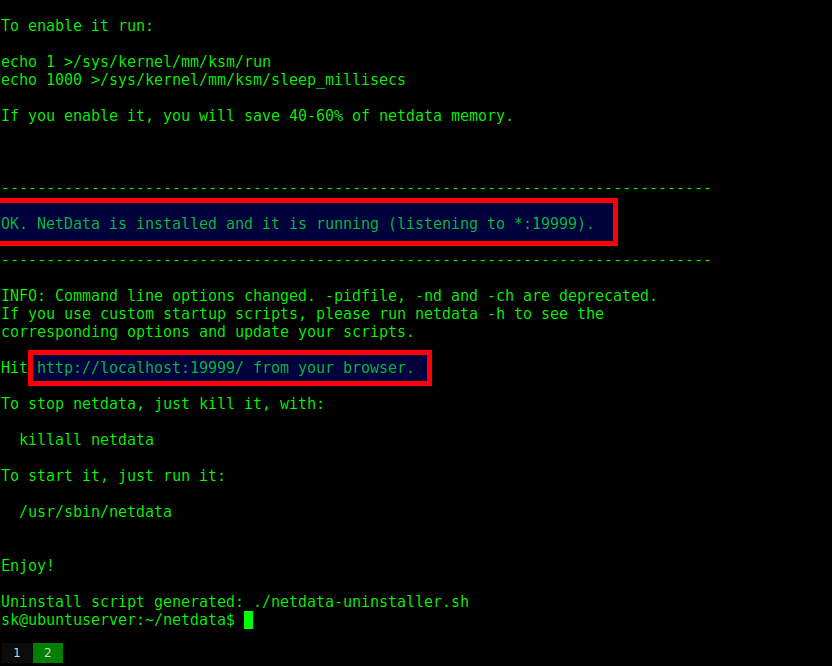
Step forward the mighty “Monit” (https://mmonit.com/monit/). By using Monit we can quickly get sophisticated watchdog-style functionality configured for our precious services and with lots of bells and whistles in addition. The Monit website even boasts that it’ll only take you fifteen minutes to get up and running. Monit cleverly covers a few key areas. It can restart a service if it fails to respond and alert you that it has done so. This also means you can monitor against resource hogs or attacks. Monit refers to these scenarios as error conditions.
As you’d expect just like a faithful watchdog Monit also enjoys service checks, launched from the standard startup directories, such as “/etc/init.d”. Additionally however the magical Monit can also keep its eagle eyes on filesystems, directories and files. The key criteria for these monitored checks being the likes of timestamps changing, checksums or file sizes altering. Monit suggests that for security purposes you could keep an eye on “md5” or “sha1” checksums of those files which should never change and trigger an alarm if they do. Clever, huh? An automated file and directory integrity checker is readily available with little effort, along the lines of packages like Tripwire or AIDE (Advanced Intrusion Detection Environment).
That’s all quite localhost-orientated but you can also keep an eye on outbound network connections to specific remote hosts. The usual suspects, TCP, UDP and Unix Domain Sockets, are supported. You can also check against the more popular protocols such as HTTP and SMTP and custom craft your own rules to send any data and patiently wait for a response if it’s not a popular protocol.
Monit is pleased to also offer the ability to capture the exit codes of scripts and programs and react if they return an unwelcome code. And last but not least Monit can track your system’s CPU, Memory and Load without breaking a sweat.
In this article we’ll look at how Monit can help you to solve your system problems. Freeing up your night times for something that all Sysadmin’s love, sleep.
Chiwawa
For such a diminutive little program there’s little doubt that Monit barks loudly with its feature-filled function list. Apparently the tiny footprint of an install is a remarkable 500kB.
Let’s get our hands dirtier and look at some of Monit’s features in action. There’s a nice install section in the FAQ which asks you to check if your system is supported before proceeding. There’s quite a list of systems on that page (https://mmonit.com/wiki/MMonit/SupportedPlatforms) including Linux (x86/x64/ARM), Mac OS X Leopard, FreeBSD 8.x or later, Solaris 11 and OpenBSD 5.5. Essentially POSIX (Portable Operating System Interface) compliant systems by all accounts. If you’re using Debbie and Ian’s favourite distribution then you might be shocked to learn that you can install Monit as so:
# apt-get install monit
Our main config file, which we’ll look at in a little while, lives here: “/etc/monit/monitrc” (you might find it living at “/etc/monit.d/monitrc” on Red Hat derivatives). If you don’t use a single config file then you can split up your configs and place them in the “/etc/monit/conf.d/” directory instead. That may make sense if you’re juggling loads of complex configurations for many services. The Configuration Management tool, Puppet (https://puppetlabs.com/), does exactly this with its manifests for example to aid clarity. First things first however. Why don’t we just dive straight in and look at some use cases? Sometimes it’s the easiest way to learn things; by getting a feel for a package’s preferred syntax. Monitoring the localhost’s system is probably a good place to start.
Monit gives us this (slightly amended) suggestion from its helpful website, which is brimming with examples incidentally, as shown in Listing One with comments to prevent eye-strain.
# Keep a beady eye on system functions
check system $HOST
if loadavg (5min) > 3 then alert
if loadavg (15min) > 1 then alert
if memory usage > 80% for 4 cycles then alert
if swap usage > 20% for 4 cycles then alert
# Test the user part of CPU usage
if cpu usage (user) > 80% for 2 cycles then alert
# Test the system part of CPU usage
if cpu usage (system) > 20% for 2 cycles then alert
# Test the i/o wait part of CPU usage
if cpu usage (wait) > 80% for 2 cycles then alert
# Test CPU usage including user, system and wait
# (CPU can be > 100% on multi-core systems)
if cpu usage > 200% for 4 cycles then alert
Listing One: How to monitor our system functions with the malleable Monit
In order to break down Listing One let’s start from the top. Clearly the “$HOST” variable is already defined and refers to the host which Monit is running on. We run through load, RAM and swap space checks initially.
Then we move onto a set of comprehensive tests used to look out for “user”, “system” and “wait” measurements. These are finished off with overall system load and a reminder that it’s quite possible these days to run CPU load up past 100% on multi-core systems.
Let’s have a peek at the monitoring config for the world’s most popular (but legendary for being insecure) Domain Name Server software, BIND (Berkeley Internet Name Domain). The example that Monit offers is BIND running in a chroot for security reasons; as we can see in Listing Two.
check process named with pidfile /var/named/chroot/var/run/named/named.pid
start program = "/etc/init.d/named start"
stop program = "/etc/init.d/named stop"
if failed host 127.0.0.1 port 53 type tcp protocol dns then alert
if failed host 127.0.0.1 port 53 type udp protocol dns then alert
Listing Two: Monit keeping an eye on your DNS Server, BIND which is running in a chroot
The main thing that I love about Monit is the logical language which it uses for its config (combined with the numerous working examples offered to make learning so much quicker). As we can see in Listing Two you can check against a Process ID file (using the top line, which begins the hierarchy for the commands under that) and then simply offer its start and stop commands underneath. Further down let’s look at the very simple conditional statements used after that. The bottom two lines achieve the same thing but refer to TCP port and UDP port instances of BIND. We’ll examine the last line in a little more detail, not that it’s unclear already:
if failed host 127.0.0.1 port 53 type udp protocol dns then alert
We can listen to open ports on our local server (127.0.0.1) and quickly specify the action to take if it’s not working, i.e. trigger an “alert”. Look at a slightly different variant using the OpenSSH Server:
if failed port 22 protocol ssh then restart
As you can see the action is to restart the services and there’s no explicit mention of “localhost” (127.0.0.1).
Bernersly
When monitoring port 80 and the all-pervasive “httpd” you are encouraged to create an empty file in your webspace which Monit can specifically check against. This cuts down on resources and there’s also a natty config setting on the Monit website to ignore these HTTP requests so that your logs don’t fill up. Let’s look at this now.
Assuming that you’re using Apache you can add these lines to the “httpd.conf” file in the logging section:
SetEnvIf Request_URI "^\/monit\/file$" dontlog
CustomLog logs/access.log common env=!dontlog
Again for use within the Monit config file you could use something along the lines of this example as seen in Listing Three (the guts of which are again available on the excellent Monit site):
check process apache with pidfile /opt/apache_misc/logs/httpd.pid
group www
start program = "/etc/init.d/apache start"
stop program = "/etc/init.d/apache stop"
if failed host localhost port 80
protocol HTTP request "/~binnie/monit/file" then restart
if failed host 192.168.1.1 port 443 type TCPSSL
certmd5 12-34-56-78-90-AB-CD-EF-12-34-56-78-90-AB-CD-EF
protocol HTTP request http://localhost/~binnie/monit/file then restart
depends on apache_bin
depends on apache_rc
Listing Three: Our Apache config for Monit which checks against an empty file and our SSL certificate’s “md5” checksum
Listing Three should hopefully make some sense now too. You can see the slight indent of the lines which follow after the “check process” line and any related config living underneath its umbrella.
The next lines start and stop the service. If you were using systemd then obviously you would replace those commands to something like this: “systemctl start apache.service”.
Getting slightly more sophisticated have a look at this nice piece of command formatting. To my admittedly addled brain the language reads just like English:
check file syslogd_file with path /var/log/syslog
if timestamp > 31 minutes then alert
Using the superb tool that is Monit we’re able to follow a specific file closely and check its timestamp. The site again gives us this excellent example. It’s more useful than you might think as examples go because it refers to a Syslog file. Syslog allows to you add a comment of sorts or a “-- MARK --” so that even when there’s no logs to add to your Syslog logfile you can tell that the ever-important logging daemon is still working correctly. Clearly adding a “-- MARK” will also boost the timestamp of that file too, which is what Monit is looking out for.
To achieve this, if you’re using the “rsyslog” daemon, you would need to open up the “/etc/rsyslog.conf” file. Then simply uncomment the line “#$ModLoad immark” to enable the “-- MARK --” functionality. Finally, preceding a quick “service rsyslog restart” or similar, inside that config file you set up how often the “-- MARK --” lines were written to the log as so:
$MarkMessagePeriod 1200
In our example the “-- MARK --” messages appear three times an hour as a result of the above entry.
This is a Raid!
Another approach is monitoring the contents of specific files and using the “match” operator. Look at this example which deals with the monitoring of software RAID:
check file raid with path /proc/mdstat
if match "\[.*_.*\]" then alert
In this case we’re inspecting what’s going on inside the “/proc/mdstat” file, which resides on the pseudo filesystem “/proc”, and hoping to match a specific expression.
Also, consider the syntax which follows below. We mentioned checking for exit codes as if you were shell scripting. Thankfully it’s much lighter work with Monit, again for checking that your software RAID is working via Nagios (https://www.nagios.org/), another popular monitoring tool which uses plugins: check program raid with path "/usr/lib/nagios/plugins/check_raid"
if status != 0 then alert
If we wanted to send out an alert when a file didn’t return the standard success code, “0”, then once more you could use the above “alert” syntax.
Let’s examine a slightly different approach for a single service now. How about if you’re worried that a particular file’s functionality gets broken for some reason and you need to check against its permissions?
Again starting to declare our config with the line containing “check”, and indenting the other lines underneath, you could do something like this for a Mail Server binary:
check file exim_bin with path /usr/sbin/exim
group mail
if failed checksum then unmonitor
if failed permission 4755 then unmonitor
if failed uid root then unmonitor
if failed gid root then unmonitor
If the file’s checksum fails or permissions are screwy (including User ID and Group ID checks) then here if any of these fail their check Monit will no longer monitor them.
If you want to reference further back into your previously defined config then you’ll see why the above example from the comprehensive Wiki which declares the “check file” config should be referred to as “exim_bin”.
Look at this example of the “depends” in Listing Four. We can see how dependencies work in Monit, it’s intuitive I’m sure that you’ll agree.
check process policyd with pidfile /var/run/policyd.pid
group mail
start program = "/etc/init.d/policyd start"
stop program = "/etc/init.d/policyd stop"
if failed port 10031 protocol postfix-policy then restart
depends on policyd_bin
depends on policyd_rc
depends on cleanup_bin
Listing Four: Showing off how dependencies work with the magical Monit
Incidentally when “unmonitor” is triggered from within its config then Monit will also ignore and disable its monitoring for any dependencies which are picked up as “depends”.
You can additionally use config syntax such as this:
if failed host mail.binnie.tld port 993 type tcpssl sslauto protocol imap for 3 cycles then restart
If you imagine that you’ve had a few problems with your inbound mail daemon and need to check against any unusual behaviour then you can also check for errors within a select time period as above within three iterations.
Mothership
You will want to chuck a few basic config commands into the main config file, namely “/etc/monit/monitrc” (a reminder it’s probably in a different location on Red Hat derivatives, please see above, near the introduction).
Now that we’ve explored the trickiest aspects of our config the rest is relatively straightforward. You will want to uncomment or explicitly change these settings in accordance with how your config file looks by default (version and distribution dependent). Look first at how to get Monit to run every three minutes:
set daemon 180
Also from within the config file you can get Monit to communicate with your Syslog server to and write logs to a sensible, central place, as so:
set logfile syslog facility log_daemon
You’ll almost certainly want to receive e-mails too and in which case you can use these lines:
set mail-format { from: alerts@binnie.tld }
set alert chris@binnie.tld
Clearly we’re configuring the “from” line in the e-mail with the first line, also known as the “sender address” in less technical circles. Two guesses what the second line does. Correct, that’s who receives the alerts.
You might optionally want to tell Monit which Mail Server to use with this following config entry for the host which Monit is running on if an SMTP service is present:
mailserver localhost
Or equally you could choose a remote Mail Server as follows:
mailserver smtp.binnie.tld
The well-considered Monit also lets us reformat the e-mails to our heart’s content. Have a look at the next section in Listing Five.
mail-format {
from: alerts@binnie.tld
subject: $SERVICE $EVENT at $DATE
message: Monit $ACTION $SERVICE at $DATE on $HOST,
$HOST is having issues with its $SERVICE service.
}
Listing Five: Thanks to Monit’s flexibility we can alter how the e-mails are formatted to less offend our sensibilities
In A Nuts Shell
If command lines are driving you nuts then you can also check out what Monit is doing through its nicely-constructed Web interface. The config file can be adjusted as follows to enable the interface:
set httpd port 3333 and
use address www.binnie.tld
This useful graphical aid can be served over either HTTP or HTTPS. You can see these adjustable settings here which would live under the “set httpd” line:
ssl enable
pemfile /usr/local/etc/monit.pem
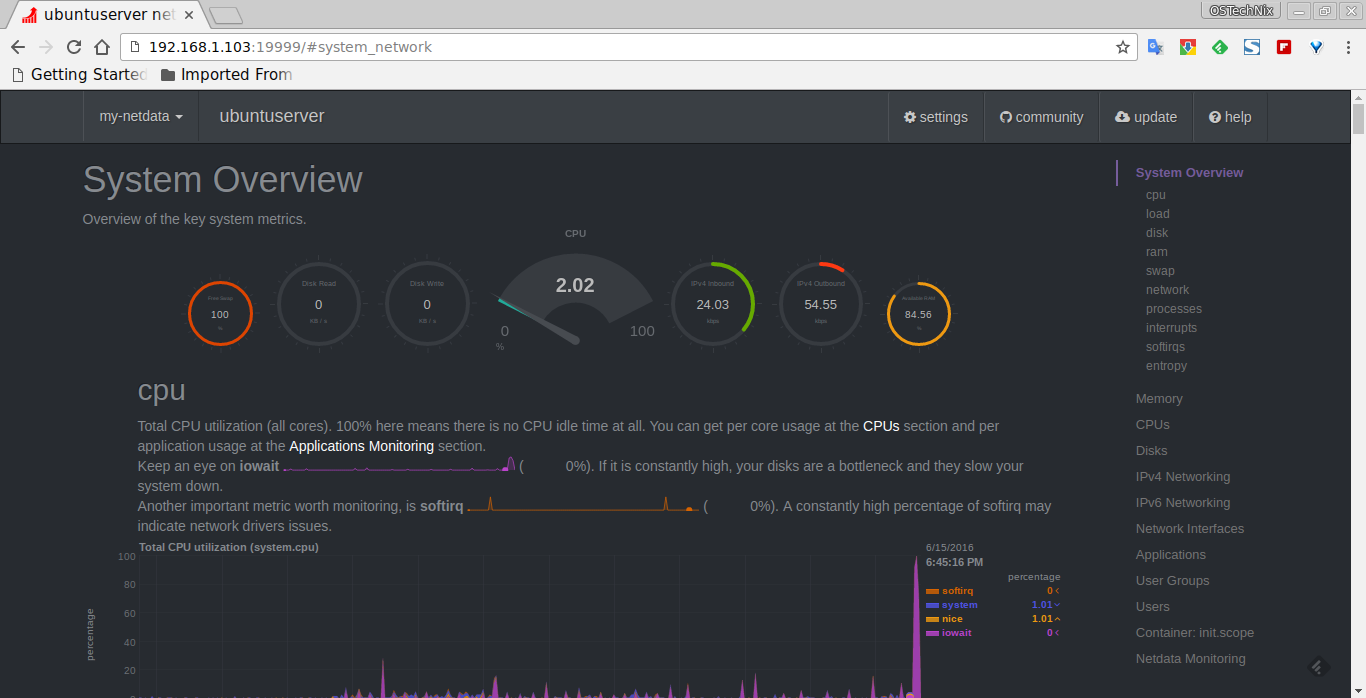
In Figure One we can see an example of the built-in Web interface which is amongst a number of interesting screenshots from Monit’s website.
![]()
Figure One: The Web interface which the excellent Monit comes with, as found on its website here:
https://mmonit.com/monit/©2001-2015 Tildeslash Ltd
There’s also some interactive functionality built into the GUI as you’d expect. Using the power of point-and-click you can stop monitoring your services and also check them manually, also known as validating a service.
Figure Two: Monit can make pretty graphs too using Monit Graph, as found at
http://dreamconception.com/tech/measure-your-server-performance-with-monit-and-monit-graph/© 2014 Dream Conception L.L.C
WIth a quick juggle of a “cron job”, making sure that PHP is present (and using “HTaccess” to protect the directory with a password if need be) you can be up and running very quickly apparently.
The features included with Monit Graph according to its GitHub page include:
- Easy to manage and customize
- Several different graphs (Google Charts) of memory, cpu, swap and alert activity
- Data logging with XML files
- Chunk rotation and size limitation
- Multiple server setup
If you need shiny graphs to compliment your command line output, and let’s not forget that you can easily combine them with the highly functional Web interface, then Monit Graph is definitely for you. Figure Three shows you other functionality that the graphing is capable of.
Keep In Touch
There’s a choice of Mailing lists to keep abreast of developments with Monit. There’s a general mailing list which can be found here:
Additionally there’s a useful list which deals with announcements:
Smarty Pants
Just when you thought that there couldn’t possibly be more to this fantastic suite of monitoring tools, here’s another.
M/Monit (https://mmonit.com/) is another good-looking, highly functional product from the same company, Tildeslash Ltd, which acts as a centralised control panel of sorts. Once you have Monit running on your individual boxes (using version 5.2 or higher) then you can then introduce a simpler way for keeping track of them all. If you’d like to check up on your systems from a smartphone then look no further. It also has a mobile version which supports iOS and Android phones.
It is funded for with a non-expiring “perpetual” licence or in other words a licence which just needs paid once. There are also paid-for support options which can be chosen as one-offs too if the need arises. The cost of owning such licences are relatively minuscule compared to other commercial products, as is M/Monit’s memory footprint. Would you believe it apparently runs super-efficiently using only 10MB of RAM and just 25MB of disk space? The docs say it can run on any POSIX system and also uses performant thread-pools and non-blocking IO too.
If Failed...
Without a shadow of doubt there’s a massive number of scenarios which Monit can help with. Those pesky developers may never have the opportunity to point their fingers in your direction again.
In this article we’ve looked at networks, processes and filesystems, all of which the magic Monit can comprehensively assist with. Coupled with its graphical capabilities and M/Monit there’s little doubt that Monit can improve your monitoring capabilities without breaking a sweat.
Sadly it’s unlikely that you’ll be in a position to *automatically* point your finger at the developers when the next problem arises. At the very least however you can automagically restore services that have failed. And, most importantly you’ll be able to achieve that without being woken up in the middle of night, whilst catching up on your beauty sleep.