https://techarena51.com/index.php/running-asynchronous-background-tasks-linux-python-3-flask-celery
![Running Asynchronous background Tasks on Linux with Python 3 Flask and Celery]()
In this tutorial I will describe how you can run asynchronous tasks on Linux using Celery an asynchronous task queue manager.
While running scripts on Linux some tasks which take time to complete can be done asynchronously. For example a System Update. With Celery you can run such tasks asynchronously in the background and then fetch the results once the task is complete.
You can use celery in your python script and run it from the command line as well but in this tutorial I will be using Flask a Web framework for Python to show you how you can achieve this through a web application.
Before we start it’s good if you have some familiarity with Flask if not you can quickly read my earlier tutorial on building Web Applications on Linux with Flask before you proceed.
This tutorial is for Python 3.4, Flask 0.10, Celery 3.1.23 and rabbitmq-server 3.2.4-1
To make it easier for you I have generated all the code required for the web interface using Flask-Scaffold and
uploaded it at https://github.com/Leo-G/Flask-Celery-Linux. You will just need to clone the code and proceed with the installation and configuration as follows:
Installation
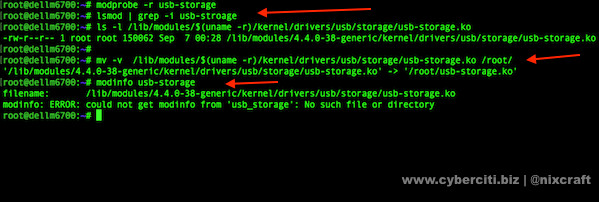
As described above the first step is to clone the code on your Linux server and install the requirements
What is RabbitMQ?
RabbitMQ is a message broker. Celery uses a message broker like RabbitMQ to mediate between clients and workers. To initiate a task, a client adds a message to the queue, which the broker then delivers to a worker. There are other message brokers as well but RabbitMQ is the recommended broker for Celery.
Configuration
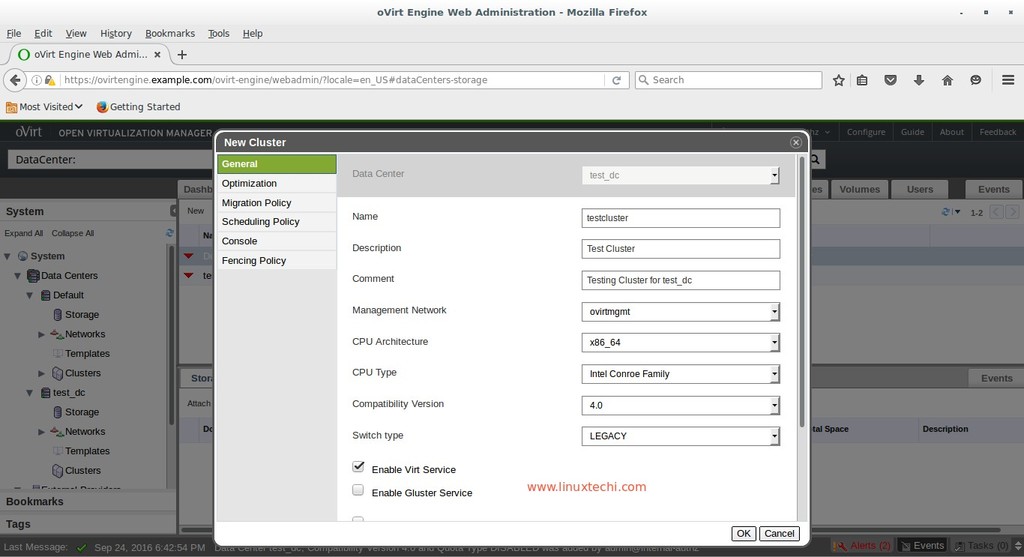
Configurations are stored in the config.py file. There are two configurations that you will need to add,
One is your database details where the state and results of your tasks will be stored and two is
the RabbitMQ message broker URL for Celery.
Database Migrations
Run the db.py script to create the database tables
![celery flask tutorial]()
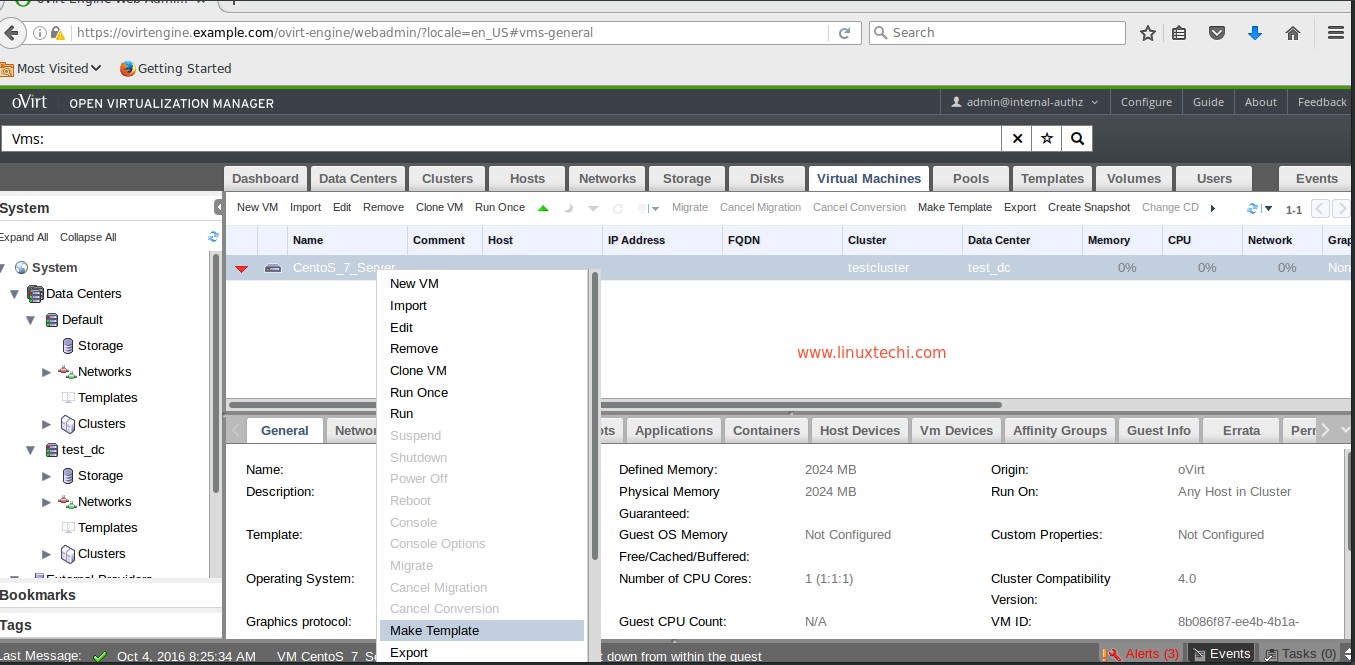
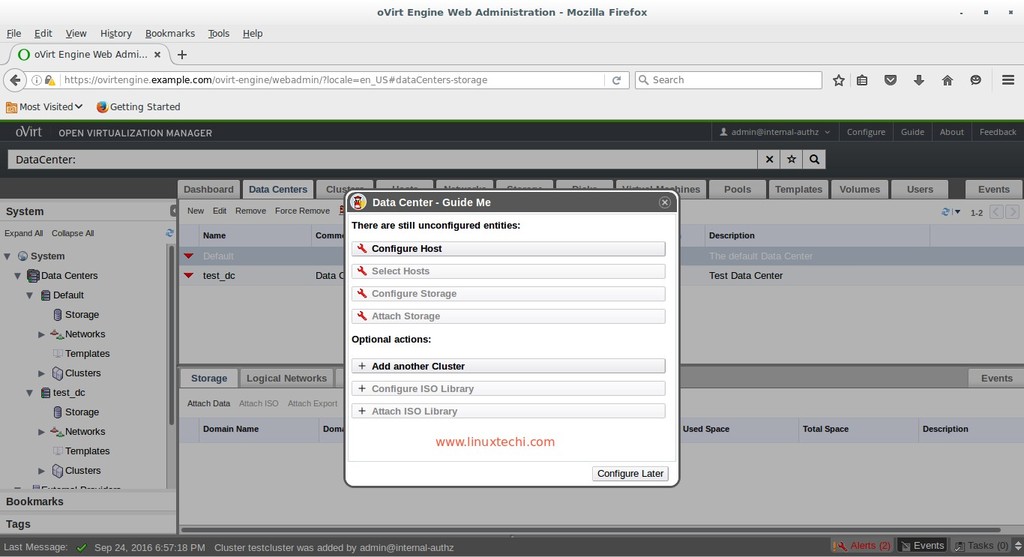
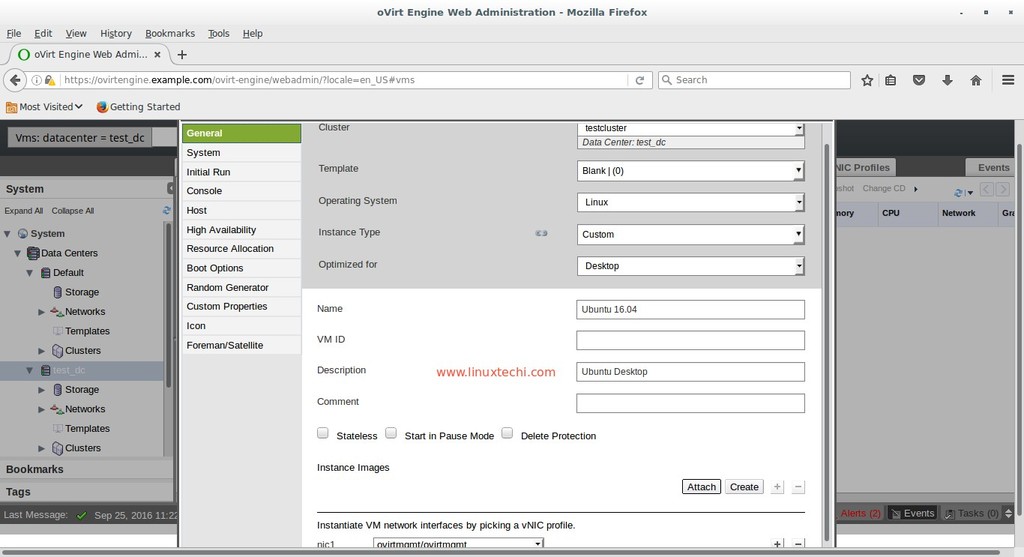
You will need to create a username and password by clicking on sign up, after which you can login.
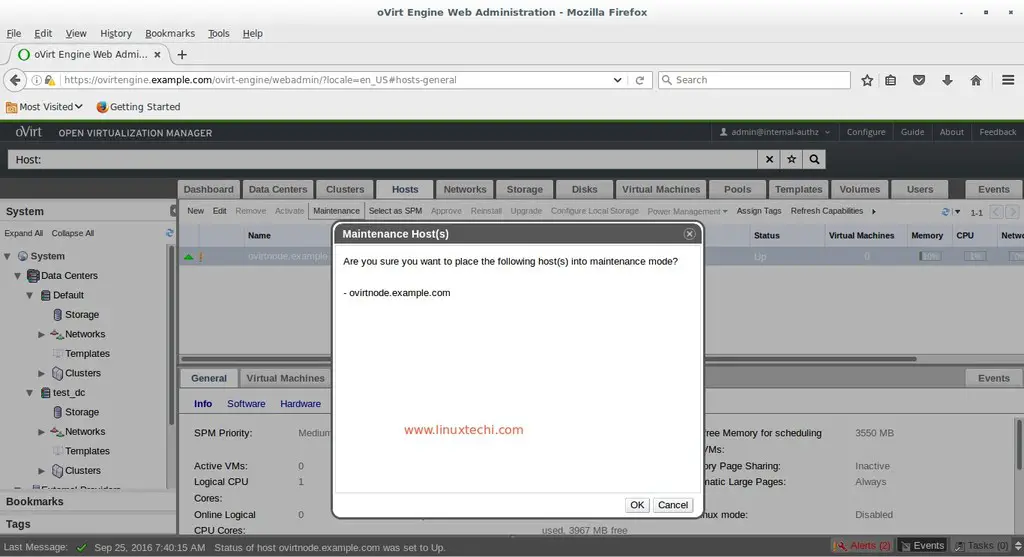
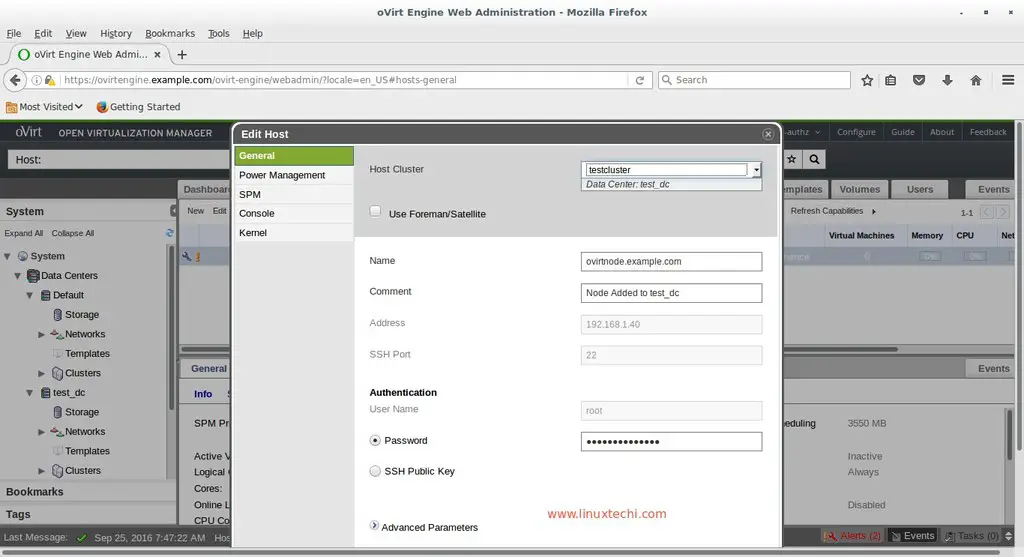
Starting the Celery Worker Process
In a new window/terminal activate the virtual environment and start the celery worker process
The video below will show you a live demonstration
Working
To integrate Celery into your Python script or Web application you first need to create an instance of
celery with your application name and the message broker URL.
Any task that has to run asynchronously then needs to be wrapped by a Celery decorator
You can then call the task in your python scripts using the ‘delay’ or ‘apply_async’ method as follows:
The difference between the ‘delay’ and the ‘apply_async()’ method is that the latter allows you to specify a time post which the task will be executed.
The above command will be executed on Linux after a 30 second delay.
In order to obtain the task status and result you will need the task id.
Tasks can have different states. Pre-defined states include PENDING, FAILURE and SUCCESS. You can
define custom states as well.
Incase a task takes a long time to execute or you want to terminate a task pre-maturely you have to use the ‘revoke’ method.
Just be sure to pass the terminate flag to it else it will be respawned when a celery worker process restarts.
Finally If you are using Flask Application Factories you will need to instantiate Celery when you create your Flask application.
To run celery in the background you can use supervisord.
That’s it for now, if you have any suggestions add them in the comments below
Ref:
http://docs.celeryproject.org/en/latest/userguide/calling.html
http://blog.miguelgrinberg.com/post/using-celery-with-flask
Images are not mine and are found on the internet

In this tutorial I will describe how you can run asynchronous tasks on Linux using Celery an asynchronous task queue manager.
While running scripts on Linux some tasks which take time to complete can be done asynchronously. For example a System Update. With Celery you can run such tasks asynchronously in the background and then fetch the results once the task is complete.
You can use celery in your python script and run it from the command line as well but in this tutorial I will be using Flask a Web framework for Python to show you how you can achieve this through a web application.
Before we start it’s good if you have some familiarity with Flask if not you can quickly read my earlier tutorial on building Web Applications on Linux with Flask before you proceed.
This tutorial is for Python 3.4, Flask 0.10, Celery 3.1.23 and rabbitmq-server 3.2.4-1
To make it easier for you I have generated all the code required for the web interface using Flask-Scaffold and
uploaded it at https://github.com/Leo-G/Flask-Celery-Linux. You will just need to clone the code and proceed with the installation and configuration as follows:
Installation
As described above the first step is to clone the code on your Linux server and install the requirements
git clone https://github.com/Leo-G/Flask-Celery-LinuxMost of the requirements including Flask and Celery will be installed using ‘pip’ however we will need to install RabbitMQ via ‘apt-get’ or your distros default package manager.
cd Flask-Celery-Linux
virtualenv -p python3.4 venv-3.4
source venv-3.4/bin/activate
pip install -r requirements.txt
sudo apt-get install rabbitmq-server
What is RabbitMQ?
RabbitMQ is a message broker. Celery uses a message broker like RabbitMQ to mediate between clients and workers. To initiate a task, a client adds a message to the queue, which the broker then delivers to a worker. There are other message brokers as well but RabbitMQ is the recommended broker for Celery.
Configuration
Configurations are stored in the config.py file. There are two configurations that you will need to add,
One is your database details where the state and results of your tasks will be stored and two is
the RabbitMQ message broker URL for Celery.
vim config.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #You can add either a Postgres or MySQL Database #I am using MySQL for this tutorialmysql_db_username ='youruser'mysql_db_password ='yourpass'mysql_db_name ='flask_celery_linux'mysql_db_hostname ='localhost'SQLALCHEMY_DATABASE_URI ="mysql+pymysql://{DB_USER}:DB_PASS}@{DB_ADDR}/{DB_NAME}".format(DB_USER=mysql_db_username, DB_PASS=mysql_db_password, DB_ADDR=mysql_db_hostname, DB_NAME=mysql_db_name)#Celery Message Broker ConfigurationCELERY_RESULT_BACKEND ="db+{}".format(SQLALCHEMY_DATABASE_URI) |
Run the db.py script to create the database tables
python db.py db initAnd finally run the in built web server with
python db.py db migrate
python db.py db upgrade
python run.pyYou should be able to see the Web Interface at http://localhost:5000

You will need to create a username and password by clicking on sign up, after which you can login.
Starting the Celery Worker Process
In a new window/terminal activate the virtual environment and start the celery worker process
cd Flask-Celery-LinuxNow go back to the Web interface and click on Commands –> New. Here you can type in any Linux command and see it run asynchronously.
source venv-3.4/bin/activate
celery worker -A celery_worker.celery --loglevel=debug
The video below will show you a live demonstration
Working
To integrate Celery into your Python script or Web application you first need to create an instance of
celery with your application name and the message broker URL.
1 2 3 4 5 | fromcelery importCeleryfromconfig importCELERY_BROKER_URLcelery =Celery(__name__, broker=CELERY_BROKER_URL) |
1 2 3 4 5 6 7 8 9 | fromapp importcelery@celery.taskdefrun_command(command): cmd =subprocess.Popen(command,stdout=subprocess.PIPE,stderr=subprocess.PIPE) stdout,error =cmd.communicate() return{"result":stdout, "error":error} |
1 2 3 | task =run_command.delay(command) |
1 | run_command.apply_async(args=[command], countdown=30) |
In order to obtain the task status and result you will need the task id.
1 2 3 4 5 6 7 8 9 10 11 12 | task =run_command.delay(cmd.split()) task_id =task.id task_status =run_command.AsyncResult(task_id) task_state =task_status.state result = str(task_status.info) #Store results in the database using SQlAlchemy frommodels importCommands command =Commands(request_dict['name'], task_id, task_state, result) command.add(command) |
define custom states as well.
Incase a task takes a long time to execute or you want to terminate a task pre-maturely you have to use the ‘revoke’ method.
1 2 | run_command.AsyncResult(task_id).revoke(terminate=True) |
Finally If you are using Flask Application Factories you will need to instantiate Celery when you create your Flask application.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | defcreate_app(config_filename): app =Flask(__name__, static_folder='templates/static') app.config.from_object(config_filename) # Init Flask-SQLAlchemy fromapp.basemodels importdb db.init_app(app) celery.conf.update(app.config)fromapp importcreate_appapp =create_app('config')if__name__ =='__main__': app.run(host=app.config['HOST'], port=app.config['PORT'], debug=app.config['DEBUG']) |
That’s it for now, if you have any suggestions add them in the comments below
Ref:
http://docs.celeryproject.org/en/latest/userguide/calling.html
http://blog.miguelgrinberg.com/post/using-celery-with-flask
Images are not mine and are found on the internet




")